We’re happy to introduce an updated Projects page on Zooniverse, designed to make it easier, faster and more enjoyable to find projects that match your interests.
The new page brings together improved navigation, long-requested features like sorting by language, and a refreshed visual design that aligns with Zooniverse’s evolving front-end experience.
One of the most requested features from our global community is finally here: project filtering by language.
Zooniverse is used by volunteers all over the world. Thanks to our amazing translators, projects are increasingly available in multiple languages. The new language filter makes it much easier to discover projects you can participate in comfortably, whether you’re looking for projects in Japanese, Czech, French, Italian or other languages.
This update helps make Zooniverse more accessible and more welcoming to the diverse community that makes participatory science possible.
Explore Projects by Organisation
The new Projects page also introduces the ability to browse projects by organisation.
On Zooniverse, organisations are research groups, institutions, observatories, universities, museums, and other teams that host and manage projects on the platform. Many organisations – such as Notes from Nature and Rubin Observatory – run multiple projects over time, often connected by shared research goals or themes.
With organisation listings now visible on the Projects page, it’s easier to discover related projects from the same research team, follow the work of organisations you’re interested in and get a clearer sense of the research communities behind the projects.
A Refreshed Look and Feel
Alongside these new features, the Projects page has been visually redesigned to match Zooniverse’s new front-end design system.
The updated layout improves consistent navigation across the platform. Project cards, filters and search tools are more clearly structured, making it simpler to scan, compare, and jump into projects that catch your eye.
This design update reflects ongoing work across Zooniverse to create a more cohesive and intuitive experience for everyone who takes part.
Built for Discovery
Whether you arrive knowing exactly what you’re looking for or just want to browse and see what’s happening across Zooniverse, the new tools are there to help you discover projects that match your interests and curiosity.
Take a look, try out the filters, explore new navigation, and enjoy the updated experience.
As the U.S. Congress deliberates on next year’s budget, proposed 50% cuts to agencies like NASA and the National Science Foundation (NSF), and the deeply concerning layoffs at the Institute of Museum and Library Services (IMLS), the National Endowment for the Humanities (NEH), and the National Endowment for the Arts (NEA), jeopardize the work of organizations like Zooniverse that rely on federal funding.
Although Zooniverse is an international collaboration, with core institutional partners in both the U.S. and the UK, this post focuses on the vital role that U.S. federal support has played in enabling our impact. As these funding decisions are made, we wanted to share how essential this support has been to Zooniverse’s impact on research and public engagement.
From the start, federal grants have been a cornerstone of Zooniverse’s ability to innovate and scale. A seed grant from the NSF in 2009 helped us explore the integration of machine learning with participatory science, work that laid the foundation for Zooniverse to become one of the world’s most sophisticated platforms for AI-enhanced crowdsourced research. A grant from IMLS advanced our Digital Humanities efforts, and a follow-on NEH grant enabled us to build critical infrastructure, like our ALICE system, for reviewing and editing transcriptions across humanities projects. Most recently, support from the National Institutes of Health (NIH) enabled a new initiative to render three-dimensional subjects within Zooniverse, expanding the platform’s capabilities to advance biomedical research.
Federal support has also been instrumental in strengthening Zooniverse’s public impacts, from an NSF Improving Undergraduate STEM Education (IUSE) grant that led to the creation of classroom.zooniverse.org to an NSF Advancing Informal STEM Learning (AISL) grant that launched a multi-person Galaxy Zoo touch table exhibit at the Adler Planetarium in Chicago. This hands-on experience reaches tens of thousands of visitors each year and often serves as the first entry point for children and their families into the world of participatory science.
Crucially, these federal grants don’t just fund abstract ideas or technologies, they fund people. Federal support helps pay the salaries of the software engineers, researchers, and participatory science professionals who build and maintain the Zooniverse platform, collaborate with research teams, and support our community of nearly 3 million volunteers.
Our current NASA grant, for example, enables over two dozen NASA research teams to unlock their datasets through Zooniverse and funds core platform maintenance efforts, an area of support notoriously difficult to secure. Our NASA grant also allowed us to respond directly to community needs through the implementation of new Group Engagement features and student service hours support, among the most requested tools from educators, classrooms, museums, and others using Zooniverse in group settings around the world.
Today, Zooniverse is part of the core infrastructure of research and scholarship. We partner with more than 150 research institutions and nearly 3 million volunteers worldwide. Our platform is a critical tool in the modern researcher’s toolkit, including in fields relying on human-in-the-loop AI methods to analyze vast datasets. At the same time, we are a trusted platform for public engagement, helping build confidence in science and fostering a sense of shared purpose across disciplines, borders, and backgrounds.
Like many research and public engagement organizations, Zooniverse has deeply benefitted from federal grant support. We felt it was important to share with our communities just how vital this support has been. Much of what we’ve built — our infrastructure, partnerships, and public-facing tools — would not have been possible without it. Continued federal investment remains critical to sustaining and growing this work.
Viewing the aurora in person is a magnificent experience, but due to location (or pesky clouds) it’s not always an option. Fortunately, citizen science projects like Aurorasaurus and Zooniverse’s Aurora Zoo make it easy to take part in aurora research from any location with an internet connection.
The Aurorasaurus Ambassadors group was excited to celebrate Citizen Science Month by inviting Dr. Daniel Whiter of Aurora Zoo to speak at our April meeting. In this post we bring you the highlights of his presentation, which is viewable in full here.
To ASK the Sky for Knowledge
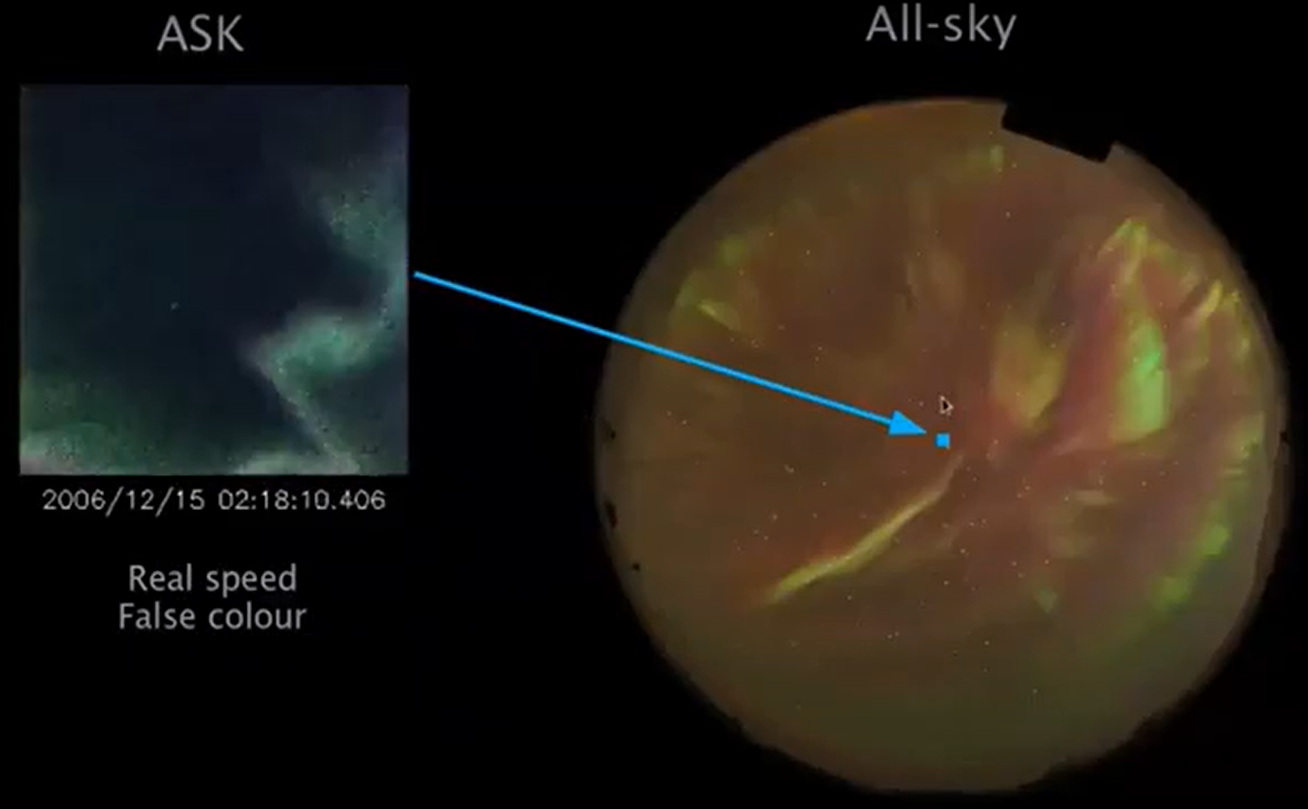
Far to the north on the Norwegian island of Svalbard, three very sensitive scientific cameras gaze at a narrow patch of sky. Each camera is tuned to look for a specific wavelength of auroral light, snapping pictures at 20 or 32 frames per second. While the cameras don’t register the green or red light that aurora chasers usually photograph, the aurora dances dynamically across ASK’s images. Scientists are trying to understand more about what causes these small-scale shapes, what conditions are necessary for them to occur, and how energy is transferred from space into the Earth’s atmosphere. ASK not only sees night-time aurora, but also special “cusp aurora” that occur during the day but are only visible in extremely specific conditions (more or less from Svalbard in the winter.)
Still from Dr. Whiter’s presentation. The tiny blue square on the allsky image (a fisheye photo looking straight up) represents the field of view of the ASK cameras. The cameras point almost directly overhead.
The setup, called Auroral Structure and Kinetics, or ASK, sometimes incorporates telescopes, similar to attaching binoculars to a camera. Project lead Dr. Daniel Whiter says, “The magnification of the telescopes is only 2x; the camera lenses themselves already provide a small field of view, equivalent to about a 280mm lens on a 35mm full frame camera. But the telescopes have a large aperture to capture lots of light, even with a small field of view.”
The challenge is that ASK has been watching the aurora for fifteen years and has amassed 180 terabytes of data. The team is too small to look through it all for the most interesting events, so they decided to ask for help from the general public.
Visiting the Aurora Zoo
Using the Zooniverse platform, the Aurora Zoo team set up a project with which anyone can look at short clips of auroras to help highlight patterns to investigate further. The pictures are processed so that they are easier to look at. They start out black and white, but are given “false color” to help make them colorblind-friendly and easier for citizen scientists to work with. They are also sequenced into short video clips to highlight movement. To separate out pictures of clouds, the data is skimmed by the scientists each day and run through an algorithm.
Aurora Zoo participants are then asked to classify the shape, movement, and “fuzziness,” or diffuse quality, of the aurora. STEVE fans will be delighted by the humor in some of the options! For example, two of the more complex types are affectionately called “chocolate sauce” and “psychedelic kaleidoscope.” So far, Aurora Zoo citizen scientists have analyzed 7 months’ worth of data out of the approximately 80 months ASK has been actively observing aurora. Check out Dr. Whiter’s full presentation for a walkthrough on how to classify auroras, and try it out on their website!
Some of the categories into which Zooniverse volunteers classify auroral movement. Credit: Dr. Daniel Whiter.
What can be learned from Aurora Zoo is different from other citizen science projects like Aurorasaurus. For example, when several arc shapes are close to one another, they can look like a single arc to the naked eye or in a photo, but the tiny patch of sky viewed through ASK can reveal them to be separate features. These tiny details are also relevant to the study of STEVE and tiny green features in its “picket fence”.
Early (Surprising!) Results
Aurora Zoo participants blew through the most recent batch of data, and fresh data is newly available. The statistics they gathered show that different shapes and movements occur at different times of day. For example, psychedelic kaleidoscopes and chocolate sauce are more common in the evening hours. The fact that the most dynamic forms show up at night rather than in the daytime cusp aurora reveals that these forms must be connected to very active aurora on the night side of the Earth.
Aurora Zoo participants also notice other structures. Several noted tiny structures later termed “fragmented aurora-like emissions,” or FAEs. Because of the special equipment ASK uses, the team was able to figure out that the FAEs they saw weren’t caused by usual auroral processes, but by something else. They published a paper about it, co-authored with the citizen scientists who noticed the FAEs.
Still from Dr. Whiter’s presentation, featuring FAEs and Aurora Zoo’s first publication.
What’s next? Now that Aurora Zoo has a lot of classifications, they plan to use citizen scientists’ classifications to train a machine learning program to classify more images. They also look forward to statistical studies, and to creating new activities within Aurora Zoo like tracing certain shapes of aurora.
STEVE fans, AuroraZoo hasn’t had a sighting yet. This makes sense, because ASK is at a higher latitude than that at which STEVE is usually seen. However, using a similar small-field technique to examine the details of STEVE has not yet been done. It might be interesting to try and could potentially yield some important insights into what causes FAEs.
Citizen Science Month, held during April of each year, encourages people to try out different projects. If you love the beautiful Northern and Southern Lights, you can help advance real aurora science by taking part in projects like Aurora Zoo and Aurorasaurus.
About the authors of this blog post: Dr. Liz MacDonald and Laura Brandt lead a citizen science project called Aurorasaurus. While not a Zooniverse project, Aurorasaurus tracks auroras around the world via real-time reports by citizen scientist aurora chasers on its website and on Twitter. Aurorasaurus also conducts outreach and education across the globe, often through partnerships with local groups of enthusiasts. Aurorasaurus is a research project that is a public-private partnership with the New Mexico Consortium supported by the National Science Foundation and NASA. Learn more about NASA citizen science here.
The volunteers on our Planet Hunters TESS project have helped discover another planetary system! The new system, HD 152843, consists of two planets that are similar in size to Neptune and Saturn in our own solar system, orbiting around a bright star that is similar to our own Sun. This exciting discovery follows on from our validation of the long-period planet around an evolved (old) star, TOI-813, and from our recent paper outlining the discovery of 90 Planet Hunters TESS planet candidates, which gives us encouragement that there are a lot more exciting systems to be found with your help!
Figure: The data obtained by NASA’s Transiting Exoplanet Survey Satellite which shows two transiting planets. The plot shows the brightness of the star HD 152843 over a period of about a month. The dips appear where the planets passed in front of the star and blocked some of its light from getting to Earth.
Multi-planet systems, like this one, are particularly interesting as they allow us to study how planets form and evolve. This is because the two planets that we have in this system must have necessarily formed out of the same material at the same time, but evolved in different ways resulting in the different planet properties that we now observe.
Even though there are already hundreds of confirmed multi-planet systems, the number of multi-planet systems with stars that are bright enough such that we can study them using ground-based telescopes remains very small. However, the brightness of this new citizen science found system, HD 152843, makes it an ideal target for follow-up observations, allowing us to measure the planet masses and possibly even probe their atmospheric composition.
This discovery was made possibly with the help of tens of thousands of citizen scientists who helped to visually inspect data obtained by NASA’s Transiting Exoplanet Survey Satellite, in the search for distant worlds. We thank all of the citizen scientists taking part in the project who continue to help with the discovery of exciting new planet systems and in particular to Safaa Alhassan, Elisabeth M. L. Baeten, Stewart J. Bean, David M. Bundy, Vitaly Efremov, Richard Ferstenou, Brian L. Goodwin, Michelle Hof, Tony Hoffman, Alexander Hubert, Lily Lau, Sam Lee, David Maetschke, Klaus Peltsch, Cesar Rubio-Alfaro, Gary M. Wilson, the citizen scientists who directly helped with this discovery and who have become co-authors of the discovery paper.
The paper has been published by the Monthly Notices of the Royal Astronomical Society (MNRAS) journal and you can find a version of it on arXiv at: https://arxiv.org/pdf/2106.04603.pdf.
This coming Saturday 13th April is Citizen Science Day, an ‘annual event to celebrate and promote all things citizen science’. Here at the Zooniverse, one of our team members will be posting each day this week to share with you their favourite Zooniverse projects. Today’s post is from Grant Miller, project manager of the Zooniverse team at the University of Oxford.
Having been at the Zooniverse for almost six years and helped over one hundred research teams launch their project on the Zooniverse platform I find it very difficult to choose just one of them as my favourtie. However, unlike Helen did on Tuesday, I’m going to give it a try 😛
For me it’s got to be the very first project that was pitched to me on my first day of the job back in 2013 – Penguin Watch! Over the last decade the lead researcher Tom Hart and his team have been travelling to the Southern Ocean and Antarctica to place time-lapse cameras looking at penguin nests. They now collect so many images each year the cannot do their science without the help of the Zooniverse crowd. This projecy perfectly demonstrates the key elements which go into making a truly great citizen science project:
It has a clear and relatable research goal: Help count penguins so we can understand how over-fishing and climate change is affecting their populations, and then use that information to influence policy makers.
It has an extremely simple task that for now can only be done accurate by human eyes: Click on the penguins in the image. It’s so simple we have 4-year-old children helping their parents do it!
It has an amazing and engaged research team and volunteer community: Even though they are a very small team the scientists take plenty of time to communicate with their volunteer community via the Talk area of the project, newsletters, and social media channels. There is also a fantastic core group of volunteer moderators who put in so much effort to make sure the project is running as well as it should.
Half a million king penguins at St Andrews Bay, South Georgia.
In addition to all of this I was lucky enough to join them on one of their Antarctic expeditions last year, as they went down to maintain their time-lapse cameras and collect the data that goes into Penguin Watch. You can see my video diary (which I’m posting once per day on the run up to World Penguin Day on the 25th April) at daily.zooniverse.org.
The team behind the Exoplanet Explorers project has just published a Research Note of the American Astronomical Society announcing the discovery of 28 new exoplanet candidates uncovered by Zooniverse volunteers taking part in the project.
Nine of these candidates are most likely rocky planets, with the rest being gaseous. The sizes of these potential exoplanets range from two thirds the size of Earth to twice the size of Neptune!
This figure shows the transit dips for all 28 exoplanet candidates. Zink et al., 2019
Finally, both the Exoplanet Explorers and Zooniverse teams would like to extend their deep gratitude to all the volunteers who took part in the project and made these amazing discoveries possible.
We recently uncovered a couple of bugs in the Zooniverse code which meant that the wrong question text may have been shown to some volunteers on Zooniverse projects while they were classifying. They were caught and a fix was released the same day on 29th November 2018.
The bugs only affected some projects with multiple live workflows from 6th-12th and 20th-29th November.
One of the bugs was difficult to recreate and relied on a complex timing of events, therefore we think it was rare and probably did not affect a significant fraction of classifications, so it hopefully will not have caused major issues with the general consensus on the data. However, it is not possible for us to say exactly which classifications were affected in the timeframe the bug was active.
We have apologised to the relevant science teams for the issues this may cause with their data analysis, but we would also like to extend our apologies to all volunteers who have taken part in these projects during the time the bugs were in effect. It is of the utmost importance to us that no effort is wasted on our projects and when something like this happens it is taken very seriously by the Zooniverse team. Since we discovered these bugs we worked tirelessly to fix them, and we have taken actions to make sure nothing like this will happen in the future.
We hope that you accept our most sincere apologies and continue the amazing work you do on the Zooniverse. If you have any questions please don’t hesitate to contact us at contact@zooniverse.org.
Hi all, I am Coleman Krawczyk and for the past year I have been working on tools to help Zooniverse research teams work with their data exports. The current version of the code (v1.3.0) supports data aggregation for nearly all the project builder task types, and support will be added for the remaining task types in the coming months.
What does this code do?
This code provides tools to allow research teams to process and aggregate classifications made on their project, or in other words, this code calculates the consensus answer for a given subject based on the volunteer classifications.
The code is written in python, but it can be run completely using three command line scripts (no python knowledge needed) and a project’s data exports.
Configuration
The first script is the uses a project’s workflow data export to auto-configure what extractors and reducers (see below) should be run for each task in the workflow. This produces a series of `yaml` configuration files with reasonable default values selected.
Extraction
Next the extraction script takes the classification data export and flattens it into a series of `csv` files, one for each unique task type, that only contain the data needed for the reduction process. Although the code tries its best to produce completely “flat” data tables, this is not always possible, so more complex tasks (e.g. drawing tasks) have structured data for some columns.
Reduction
The final script takes the results of the data extraction and combine them into a single consensus result for each subject and each task (e.g. vote counts, clustered shapes, etc…). For more complex tasks (e.g. drawing tasks) the reducer’s configuration file accepts parameters to help tune the aggregation algorithms to best work with the data at hand.
A full example using these scripts can be found in the documentation.
Future for this code
At the moment this code is provided in its “offline” form, but we testing ways for this aggregation to be run “live” on a Zooniverse project. When that system is finished a research team will be able to enter their configuration parameters directly in the project builder, a server will run the aggregation code, and the extracted or reduced `csv` files will be made available for download.
Occasionally we run studies in collaboration with external researchers in order to better understand our community and improve our platform. These can involve methods such as A/B splits, where we show a slightly different version of the site to one group of volunteers and measure how it affects their participation, e.g. does it influence how many classifications they make or their likelihood to return to the project for subsequent sessions?
One example of such a study was the messaging experiment we ran on Galaxy Zoo. We worked with researchers from Ben Gurion University and Microsoft research to test if the specific content and timing of messages presented in the classification interface could help alleviate the issue of volunteers disengaging from the project. You can read more about that experiment and its results in this Galaxy Zoo blog post https://blog.galaxyzoo.org/2018/07/12/galaxy-zoo-messaging-experiment-results/.
As the Zooniverse has different teams based at different institutions in the UK and the USA, the procedures for ethics approval differ depending on who is leading the study. After recent discussions with staff at the University of Oxford ethics board, to check our procedure was up to date, our Oxford-based team will be changing the way in which we gain approval for, and report the completion of these types of studies. All future study designs which feature Oxford staff taking part in the analysis will be submitted to CUREC, something we’ve been doing for the last few years. From now on, once the data gathering stage of the study has been run we will provide all volunteers involved with a debrief message.
The debrief will explain to our volunteers that they have been involved in a study, along with providing information about the exact set-up of the study and what the research goals were. The most significant change is that, before the data analysis is conducted, we will contact all volunteers involved in the study allow a period of time for them to state that they would like to withdraw their consent to the use of their data. We will then remove all data associated with any volunteer who would not like to be involved before the data is analysed and the findings are presented. The debrief will also contain contact details for the researchers in the event of any concerns and complaints. You can see an example of such a debrief in our original post about the Galaxy Zoo messaging experiment here https://blog.galaxyzoo.org/2015/08/10/messaging-test/.
As always, our primary focus is the research being enabled by our volunteer community on our individual projects. We run experiments like these in order to better understand how to create a more efficient and productive platform that benefits both our volunteers and the researchers we support. All clicks that are made by our volunteers are used in the science outcomes from our projects no matter whether they are part of an A/B split experiment or not. We still strive never to waste any volunteer time or effort.
We thank you for all that you do, and for helping us learn how to build a better Zooniverse.
The US virgin Islands as seen from ESA’s Sentinel-2 satellite on 23rd August 2017. Pre-storm imagery like this is used to compare to post-storm images in order to spot major changes.
Irma has brought widespread devastation to many islands in the Caribbean over the last few days, and now Hurricane Jose is a growing threat in the same region.
By analysing images of the stricken areas captured by ESA’s Sentinel-2 satellites, Zooniverse volunteers can provide invaluable assistance to rescue workers. Rescue Global are a UK-based disaster risk reduction and response charity who are deploying a team to the Caribbean and will use the information you provide to help them assess the situation on the ground.
The last time The Planetary Response Network was brought online was to help in the aftermath of the 2016 Ecuador Earthquake. Back then over two thousand volunteers helped analyse almost 25,000 square kilometres of satellite imagery in only 12 hours, and we hope to be of help this time too!
Right now we have limited clear-sky images of the affected area, mostly around Guadeloupe, but we are working hard to upload images from the other islands as soon as possible.
The world's largest and most popular platform for people-powered research. This research is made possible by volunteers—millions of people around the world who come together to assist professional researchers.