
Below is a guest post from a researcher who has been studying the Zooniverse and who just published a paper called ‘Crowdsourced Science: Sociotechnical epistemology in the e-research paradigm’. That being a bit of a mouthful, I asked him to introduce himself and explain – Chris.
My name is David Watson and I’m a data scientist at Queen Mary University of London’s Centre for Translational Bioinformatics. As an MSc student at the Oxford Internet Institute back in 2015, I wrote my thesis on crowdsourcing in the natural sciences. I got in touch with several members of the Zooniverse team, who were kind enough to answer all my questions (I had quite a lot!) and even provide me with an invaluable dataset of aggregated transaction logs from 2014. Combining this information with publication data from a variety of sources, I examined the impact of crowdsourcing on knowledge production across the sciences.
Last week, the philosophy journal Synthese published a (significantly) revised version of my thesis, co-authored by my advisor Prof. Luciano Floridi. We found that Zooniverse projects not only processed far more observations than comparable studies conducted via more traditional methods—about an order of magnitude more data per study on average—but that the resultant papers vastly outperformed others by researchers using conventional means. Employing the formal tools of Bayesian confirmation theory along with statistical evidence from and about Zooniverse, we concluded that crowdsourced science is more reliable, scalable, and connective than alternative methods when certain common criteria are met.
In a sense, this shouldn’t really be news. We’ve known for over 200 years that groups are usually better than individuals at making accurate judgments (thanks, Marie Jean Antoine Nicolas de Caritat, aka Marquis de Condorcet!) The wisdom of crowds has been responsible for major breakthroughs in software development, event forecasting, and knowledge aggregation. Modern science has become increasingly dominated by large scale projects that pool the labour and expertise of vast numbers of researchers.
We were surprised by several things in our research, however. First, the significance of the disparity between the performance of publications by Zooniverse and those by other labs was greater than expected. This plot represents the distribution of citation percentiles by year and data source for articles by both groups. Statistical tests confirm what your eyes already suspect—it ain’t even close.
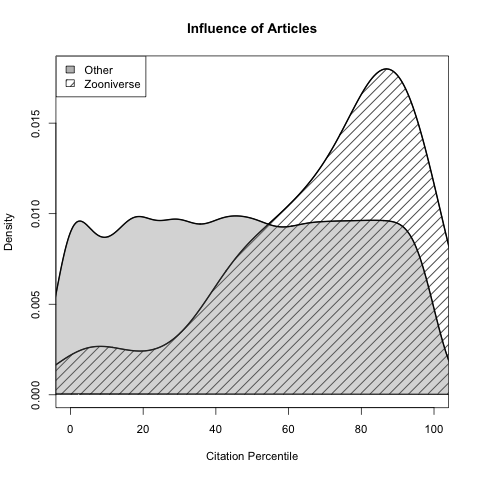
We were also impressed by the networks that appear in Zooniverse projects, which allow users to confer with one another and direct expert attention toward particularly anomalous observations. In several instances this design has resulted in patterns of discovery, in which users flag rare data that go on to become the topic of new projects. This structural innovation indicates a difference not just of degree but of kind between so-called “big science” and crowdsourced e-research.
If you’re curious to learn more about our study of Zooniverse and the site’s implications for sociotechnical epistemology, check out our complete article.
