By Lola Fash, Guest Writer and Adler Zooniverse Summer ’22 Teen Intern
This summer I had the opportunity to be a Zooniverse intern at the Adler Planetarium in Chicago, with two other interns, Tasnova and Dylan. As a group, we carried out a series of interviews with researchers leading Zooniverse projects. My focus project was the NASA GLOBE Cloud Gaze on Zooniverse. I led the interview with NASA scientist Marilé Colón Robles, the principal investigator for the project, and Tina Rogerson, the co-investigator and data analyst for the project.

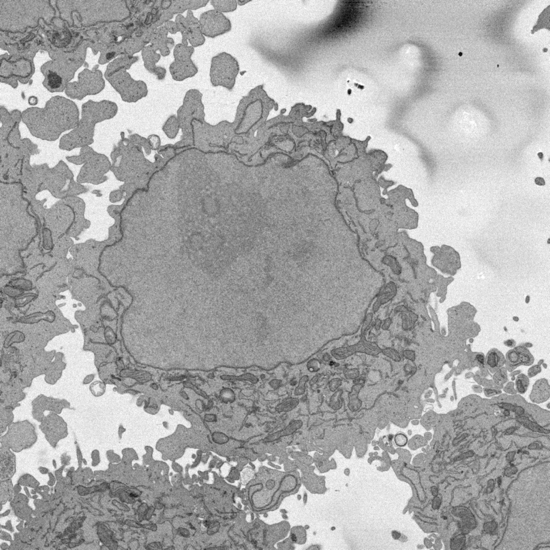
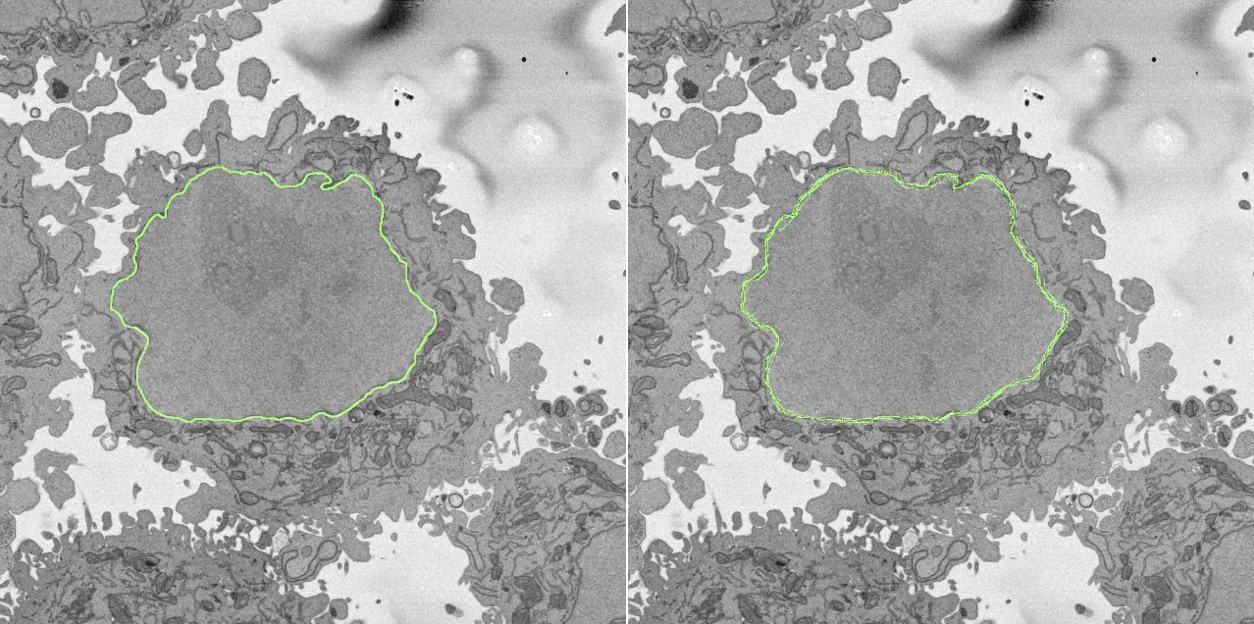
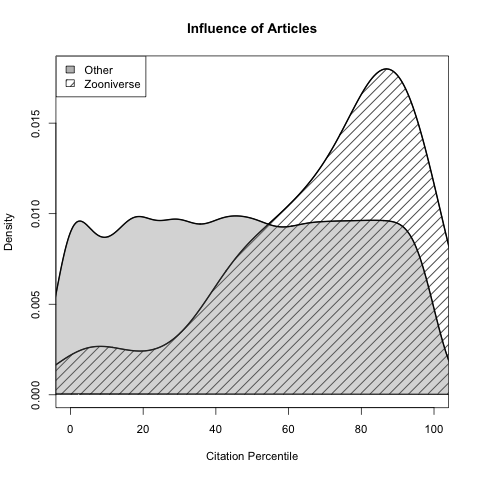
NASA GLOBE Cloud Gaze is a collaboration between the Global Learning and Observations to Benefit the Environment (GLOBE) Program, NASA’s largest citizen science program, and Zooniverse. When NASA began to study clouds to understand how they affect our climate, they launched about 20 satellites to collect data on Earth’s clouds. Unfortunately, these satellites are limited to only collecting data from above the clouds, which only paints half of the picture for scientists. They needed data from the ground to complete the picture. In 2018, they launched the first ever cloud challenge on GLOBE Clouds, which asked people all over the world to submit observations of clouds and photographs of their sky through the GLOBE Observer app. People responded faster than expected, submitting over 50,000 observations across 99 different countries during the month-long challenge. Because of the high volume, it would take months for researchers alone to go through each submission. So instead, they sought help, thus birthing the Zooniverse CLOUD GAZE project, where people help them classify these photos. Zooniverse participants classify the photos by cloud cover (what percent of the sky is covered by clouds), what type of cloud is in the image, and if they see any other conditions like haze, fog, or dust.
Why are clouds so important?
We see the immediate effects of these clouds in our atmosphere. For example, when you go out on a sunny day and the sun gets blocked by low altitude clouds, you feel cooler right away. But rather than looking at short-term effects, the CLOUD GAZE project is working to understand the long-term role clouds play on our climate.
Clouds play a significant role in maintaining Earth’s climate. They control Earth’s energy budget, the balance between the energy the Earth receives from the Sun and the energy the Earth loses back into outer space, which determines Earth’s temperature. The effects clouds have varies by type, size, and altitude.
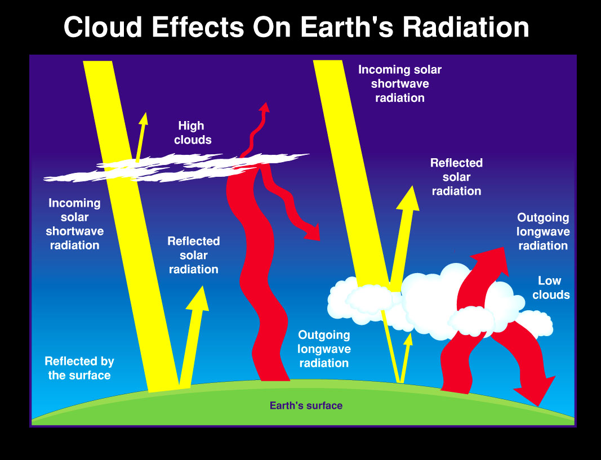
Cirrus, cirrostratus, and cirrocumulus clouds are high altitude clouds that allow incoming radiation to be absorbed by Earth, then trap it there, acting like an insulator and increasing Earth’s temperature. Low altitude clouds, such as stratus and cumulonimbus, keep our planet from absorbing incoming radiation, and allow it to radiate energy back into space.
The classifications made by Zooniverse participants are needed to determine the amount of solar radiation that is reflected or absorbed by clouds before reaching the surface of Earth and how that correlates to climate over time.
In my interview, I had the honor to meet with NASA Scientists Marilé Colón Robles and Tina Rogerson, learn more about the NASA GLOBE Cloud Gaze effort, and hear their predictions for the future.
Clip 1: Introductions
This first clip is of Marilé, Tina, and me introducing ourselves to one another. Note: The other participants you’ll see in the recordings are Sean Miller (Zooniverse designer and awesome mentor for us interns) and Dylan and Tasnova (my fellow interns).
Clip 2: What prompted you to start NASA GLOBE Cloud Gaze on Zooniverse?
Quote from Tina from this Clip 2: “We have 1.8 million photographs of the sky. We want to know what’s in those photographs.”
Clip 3: What have your GLOBE participants been telling you about what they’re seeing in their local environments about the impacts of climate change?
What are your hopes and goals for this project?
In the interview, I asked them about their hopes and broader goals for the project. They talked about how in order to really understand climate change, we need to gather the best data possible. The majority of the data we have on clouds are from the 20th century. One of the project goals was to update our databases on clouds in order to conduct proper research on climate change. Tina Rogerson, Cloud Gaze’s data analyst, gathers this information and compiles it into easily accessible files. The files include data from a range of different sources: satellites, Globe observations, and Zooniverse classifications (see https://observer.globe.gov/get-data). They give people a chance to analyze clouds at different points and connect the dots to analyze the whole.
Scientist Marilé Colón Robles explained that one of the goals of the project is to make a climatology of cloud types based on the data they have collected. This would help us have a record on how the clouds have changed in a given location in relation to the climate of that area. We would have information on the entire world, every single continent, yes, including Antarctica.
Why did I pick this project to focus on?
I chose this project because I wanted to challenge myself. I have always shied away from topics and conversations about climate change and global warming. I felt I could never fully comprehend it so I should instead avoid it by all means possible. My fellow interns and I had three projects to choose from: Transcribe Color Convention, Active Asteroids, and NASA GLOBE CLOUD GAZE. If it were any other day, I would have chosen one of the first two projects to be my focus but I wanted to change, to try something new. The only way to grow is to step out of your comfort zone and I am so glad I did.
People make the mistake of believing that climate change can’t be helped and that after our Earth becomes inhabitable we can just pull a Lost In Space and find a different planet to live on. I had the chance to speak with Dr. Michelle B. Larson, CEO of Adler Planetarium, and we talked about how there isn’t another planet for us to go to if we mess this one up. Even if there was, it would take years and a lot of resources to ready the planet for ourselves. Those are resources and years that we could be spending on fixing our home.
The CLOUD GAZE focused on one of the most important and understudied factors in Earth’s climate – clouds. People all over the world are helping in their own way to help save the planet. Some make sure to always recycle their garbage. Some take public transportation more often, and switch to electronic vehicles to cut down on their carbon footprint. You and I can help by taking pictures of our sky, submitting it in the GLOBE Observer app, and by going to the Zooniverse Cloud GAZE project, classifying as little as 10 images of clouds per day to multiply the data on clouds, which in turn helps further our research and our understanding of climate change.