I recently released version 1.1 of the Panoptes CLI – the command-line interface for managing Zooniverse projects. This update includes some exciting new features. Here are the highlights.
You can install the update by running pip install -U panoptescli. Any bugs or issues should be raised via GitHub. See the changelog for the full list of changes.
Resuming failed subject uploads
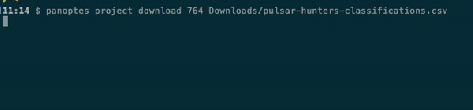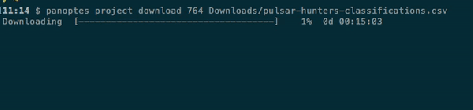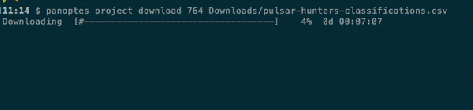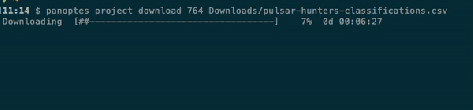
This one adds what is probably the CLI’s most requested feature: the ability to resume a failed upload from where it left off, without duplicating subjects or requiring manual changes to the manifest. I hope this will be a huge help to researchers, especially when uploading large manifests.
If the upload fails for any reason – whether that’s an issue with our systems, a problem with your internet connection, a bug in the CLI itself, or if you just decide to stop the upload by pressing ctl-c – the CLI will detect that there was a problem and will ask you if you want to be able to resume the upload later. If you say yes, it will then save a new manifest in YAML format containing the remaining upload queue along with all of the upload’s command line options. Then to resume, you just start a new upload with the YAML manifest instead of the original CSV.
Multithreaded subject uploads
Uploading new subjects can often take a long time. The total upload time depends not only on your internet connection speed, but also on the time it takes for the CLI to talk to the Panoptes API. Creating a new subject typically requires the CLI to make two HTTP requests: one to create the subject and one to upload the subject’s media (the image, or video, or whatever). If the subject has multiple images then that only increases the number of requests. Plus subjects need to be linked to the subject set; this happens in batches, but it can still add up to a lot of requests for large uploads. If you’re uploading 10,000 subjects for example, that means the CLI has to make a minimum of 20,000 requests (probably more), and each of those requests includes some overhead where the CLI is waiting for the server to respond, which is all basically wasted time.
Luckily the Panoptes CLI 1.1 gets around that, by taking advantage of the multithreading features of the Panoptes Client for Python which were released earlier this year. Now, those 20,000 requests will happen five at a time, so for example three of them can be sending data while two of them are waiting for the server, meaning your internet connection is fully utilised the whole time and no time is wasted. In my testing, this substantially sped up subject uploads, potentially saving hours of your time.
Adding and removing lists of subjects to and from subject sets
Often project owners need to add large numbers of existing subjects to a new set, or remove subjects from their current set. It was possible to do this with the previous version of the CLI by passing subject IDs on the command-line, but it was often difficult to modify large numbers of subjects this way (it was possible with xargs on Linux and macOS, but this isn’t the most intuitive way to do it).
Now, there’s a new option to pass a list of IDs in a text file rather than having to specify IDs on the command-line. (The old way is still there too if you prefer to do it that way!) Just produce a text file containing the relevant subject IDs, one per line. If you already have the subject information in a spreadsheet, exporting a CSV file with just the subject ID column will produce the right file (just make sure it only contains the one column).
For example, if you have a file called subject_ids.csv containing the following:
1234 5678 9012
You can run:
panoptes subject-set add-subjects -f subject_ids.csv 1357
to add subjects 1234, 5678, and 9012 to subject set 1357.
Edited 29 November 2019: Fixed typo in pip command for upgrade.