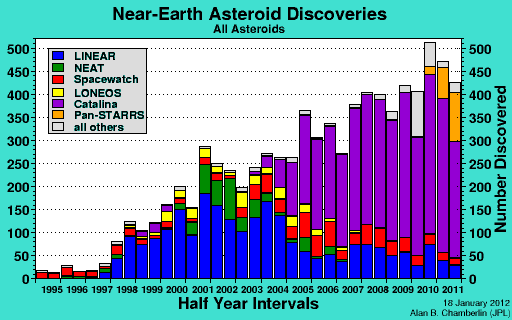
We talk a lot in the Zooniverse about research, whether it’s interesting stories from the community, a new paper based upon the combined efforts of the volunteers and the science teams or conferences we might be going to.
One thing we don’t spend much time talking about is the technology solutions we use to build the Zooniverse sites, the lessons we’ve learned as a team building more than twenty five citizen science projects over the past five years and where we think the technical challenges still remain in building out the Zooniverse into something bigger and better.
There’s a lot to write here so I’m going to break this into three separate blog posts. The first is going to be entirely about the domain model that we use to describe what we do. When it seems relevant I’ll talk a little more about implementation details of these domain entities in our code too. The second will be about technologies and the infrastructure we run the Zooniverse atop of and the third will be about making smarter systems.
Why bother with a domain model?
Firstly it’s worth spending a little time talking about why we need a domain model. In my mind the primary reason for having a domain model is that it gives the team, whether it’s the developers, scientists, educators or designers working on a new project a shared vocabulary to talk about the system we’re building together. It means that when I use the term ‘Classification’ everyone in the team understands that I’m talking about the thing we store in the database that represents a single analysis/interaction of a Zooniverse volunteer with a piece of data (such as a picture of a galaxy), which by the way we call a ‘Subject’.
Technology wise the Zooniverse is split into a core set of web services (or Application Programming Interface, API) that serve up data and collect it back (more about that later) and some web applications (the Zooniverse projects) that talk to these services. The domain model we use is almost entirely a description of the internals of the core Zooniverse API called Ouroboros and this is an application that is designed to support all of the Zooniverse projects which means that some of the terms we use might sound overly generic. That’s the point.
The core entities
The domain model is actually pretty simple. We typically think most about the following entities:
User
People are core to the Zooniverse. When talking publically about the Zooniverse I almost always use the term ‘citizen scientist’ or ‘volunteer’ because it feels like an appropriate term for someone who donates their time to one of our projects. When writing code however, the shortest descriptive term that makes sense is usually selected so in our domain model the term we use is User.
A User is exactly what you’d expect, it’s a person, it has a bunch of information associated with it such as a username, an email address, information about which projects they’ve helped with and a host of other bits and bobs. Crucially though for us, a User is the same regardless of which project they’re working – that is Users are pan-Zooniverse. Whether you’re classiying galaxies over at Galaxy Zoo or identifying animals on Snapshot Serengeti we’re associating your efforts with the same User record each time which turns out to be useful for a whole bunch of reasons (more later).
Subject
Just as people are core, as are the things that they’re analysing to help us do research. In Old Weather it’s a scanned image of a ship log book, in Planet Hunters it’s a light curve but regardless of the project internally we call all of these things Subjects. A Subject is the thing that we present to a User when we want to them to do something.
Subjects are one of the core entities that we want to behave differently in our system depending upon their particular flavour. A log book in Old Weather is only viewed three times before being retired whereas an image in Galaxy Zoo is shown more than 30 times before retiring. This means that for each project we have a specific Subject class (e.g. GalaxyZooSubject) that inherits its core functionality from a parent Subject class but then extends the functionality with the custom behaviour we need for a particular project.
Subjects are then stored in our database with a collection of extra information a particular Subject sub-class can use for each different project. For example in Galaxy Zoo we might store some metadata associated with the survey telescope that imaged the galaxy and in Cyclone Center we store information about the date, time and position the image was recorded.
Workflow/Task
These two entities are grouped together as they’re often used to mean broadly the same thing. When a User is presented with a Subject on one of our projects we ask them to do something. This something is called the Task. These Tasks can be grouped together into a Workflow which is essentially just a grouping entity. To be honest we don’t use it very much as most projects just have a single Workflow but in theory it allows us to group a collection of Tasks into a logical unit. In Notes from Nature each step of the transcription (such as ‘What is the location?’) is a separate Task, in Galaxy Zoo, each step of the decision tree is a Task too.
Classification
It’s no accident that I’ve introduced these three entities, User, Subject and Task first as a combination of these is what we call a Classification. The Classification is the core unit of human effort produced by the Zooniverse community as it represents what a person saw and what they said about it. We collect a lot of these – across all of the Zooniverse projects to date we must be getting close to 500 million Classifications recorded.
I’ll talk more about what we store in a Classification in a followup the next post about technologies suffice to say now that they store a full description of what the User said about the object. In previous versions of the Zoonivese API software we tried to break these records out into smaller units called Annotations but we don’t do that any more – it was an unnecessary step.

Group
Sometimes we need to group Subjects together for some higher level function. Perhaps it’s to represent a season’s worth of images in Snapshot Serengeti or a particular cell dye staining in Cell Slider. Whatever the reason for grouping, the entity we use to describe this is ‘Group’.
Grouping records is both one of the most useful features Ouroboros offers but also one of the things it took the longest for us to find the right level of abstraction. While a Group can represent an astronomical survey in Galaxy Zoo (such as the Hubble CANDELS survey) or a Ship in Old Weather, it isn’t just enough for a bunch of Subjects to all be associated with each other. There’s often a lots of functionality that goes along with a Group or the Subjects within that is custom for each Zooniverse project. Ultimately we’ve solved this in a similar fashion to Subject – by having per-project subclasses of Groups (i.e. there is a SerengetiGroup that inherits from Group) that can set custom behaviour as required.
Project
Ouroboros (the Zooniverse API) hosts a whole bunch of different Zooniverse projects so it’s probably no surprise that we represent the actual citizen science project within our domain model. No prize for guessing the name of this entity – it’s called Project.
A Project is really just the overarching named entity that Subjects, Classifications and Groups are associated with. Project in Ouroboros does some other cool stuff for us though. It’s the Project that knows about the Groups, its current status (such as how many Subjects are complete) and other adminstrative functions. We also sometimes deliver a slightly different user experience to different Users in what are known as A/B splits – it’s the Project that manages these too.
So that’s about it. There are a few more entities routinely in discussion in the Zooniverse team such as Favourite (something a User favourites when they’re on one of our projects) but they’re really not core to the main operation of a project.
The domain description we’re using today is informed by everthing we’ve learnt over the past five years of building proejcts. It’s also a consequence of how the Zooniverse has been functioning – we try lots of projects in lots of different research domains and so we need a domain model that’s flexible enough to support something like Notes from Nature, Planet Four and Snapshot Seregeti but not so generic that we can’t build rich user experiences.
We’ve also realised that the vast majority of what’s differenct about each project is the user experience and classification interface. We’re always likely to want to put significant effort into developing the best user experience possible and so having an API that abstracts lots of the complexity away and allows us to focus on what’s different about each project is a big win.
Our domain model has also been heavily influenced by the patterns that have emerged working with science teams. In the early years we spent a lot of time abstracting out each step of the User interaction with a Subject into distinct descriptive entities called Annotations. While in theory these were a more ‘complete’ description of what a User did, the science teams rarely used them and almost never in realtime operations. The vast majority of Zooniverse projects to date collect large numbers of Classifications that are write once, read very much later. Realising this has allowed us to worry less about exactly what we’re storing at a given time and focus on storing data structures that are a convenient for the scientists to work with.
Overall the Zooniverse domain model has been a big success. When designing for the Zooniverse we really were developing a new system unlike anything else we knew of. It’s terminology is pervasive in the collaboration and makes conversations much more focussed and efficient which can only be a good thing.