In this edition of Who’s who in the Zoo, meet Michelle Yuen, a Zooniverse backend developer.
Who: Michelle Yuen, Backend developer at Zooniverse
Location: Adler Planetarium, Chicago USA
Zooniverse projects: Panoptes, ERAS (Stats service), Talk API, Caesar
What’s something people might not expect about your job or daily routine?
People assume I just sit and code all day, but most of my time is spent playing detective with invisible problems—tracking down mysterious server crashes, optimizing data no one ever sees, or convincing stubborn APIs to behave. Basically, I fight invisible fires and hope no one notices.
Outside of work, what do you enjoy doing?
Outside of work, I enjoy playing tennis and pickleball. I enjoy cuddling with my cat, Bela. I love all things Disney and am also a cozy gamer—I’m currently hooked on Dreamlight Valley. I’m passionate about baking and often bring in my test recipes and treats for my colleagues at the Adler to try.
What are you favourite citizen science projects?
I’ve enjoyed working with Active Asteroids in the past and even spoke about Zooniverse at a tech conference, where I highlighted what the classification process looks like using Active Asteroids as an example project (you can learn more here).
What guidance would you give to other researchers considering creating a citizen research project?
Remember that community matters. Treating volunteers as partners, staying engaged, and sharing progress helps make the experience rewarding for everyone involved 🙂
Is there anything else you’d like to share with our readers?
It’s really wonderful to see how thoughtful and engaged the Zooniverse community is—from volunteers to researchers and everyone in between. The genuine enthusiasm people bring to supporting and advancing research is incredibly meaningful. I’m deeply grateful to be part of this community; it truly makes coming to work each day a joy.
We’re happy to introduce an updated Projects page on Zooniverse, designed to make it easier, faster and more enjoyable to find projects that match your interests.
The new page brings together improved navigation, long-requested features like sorting by language, and a refreshed visual design that aligns with Zooniverse’s evolving front-end experience.
One of the most requested features from our global community is finally here: project filtering by language.
Zooniverse is used by volunteers all over the world. Thanks to our amazing translators, projects are increasingly available in multiple languages. The new language filter makes it much easier to discover projects you can participate in comfortably, whether you’re looking for projects in Japanese, Czech, French, Italian or other languages.
This update helps make Zooniverse more accessible and more welcoming to the diverse community that makes participatory science possible.
Explore Projects by Organisation
The new Projects page also introduces the ability to browse projects by organisation.
On Zooniverse, organisations are research groups, institutions, observatories, universities, museums, and other teams that host and manage projects on the platform. Many organisations – such as Notes from Nature and Rubin Observatory – run multiple projects over time, often connected by shared research goals or themes.
With organisation listings now visible on the Projects page, it’s easier to discover related projects from the same research team, follow the work of organisations you’re interested in and get a clearer sense of the research communities behind the projects.
A Refreshed Look and Feel
Alongside these new features, the Projects page has been visually redesigned to match Zooniverse’s new front-end design system.
The updated layout improves consistent navigation across the platform. Project cards, filters and search tools are more clearly structured, making it simpler to scan, compare, and jump into projects that catch your eye.
This design update reflects ongoing work across Zooniverse to create a more cohesive and intuitive experience for everyone who takes part.
Built for Discovery
Whether you arrive knowing exactly what you’re looking for or just want to browse and see what’s happening across Zooniverse, the new tools are there to help you discover projects that match your interests and curiosity.
Take a look, try out the filters, explore new navigation, and enjoy the updated experience.
In this edition of Who’s who in the Zoo, meet Oluwatoyosi Oyegoke, a Zooniverse backend developer.
Who: Oluwatoyosi Oyegoke, Backend developer at Zooniverse
Location: University of Oxford
Zooniverse projects: Panoptes API, Panoptes Python Client & CLI, KaDE (Knowledge and Discovery Engine), BaJor (Azure Batch Job Runner), Active Learning Pipelines
What is your research about?
My work focuses on helping scientists manage the huge amount of data created by Zooniverse projects. These projects can produce millions of images from telescopes, wildlife cameras, or research surveys. Volunteers classify these images, and I build the systems that collect this information and make it useful for researchers.
I work on the Panoptes API, which is the core platform that stores project data and volunteer classifications. I also improve the Python client and CLI so researchers can easily access and analyse their data. Another part of my role involves building and maintaining the machine learning pipelines. These pipelines take the volunteer classifications, train models, run predictions, and manage large Azure Batch jobs.
In simple terms: scientists and volunteers create the data, machine learning tries to learn from it, and I build the tools and backend systems that help everything work together smoothly. My work makes it easier for researchers to understand very large datasets by improving the platforms and workflows behind the scenes.
How do Zooniverse volunteers contribute to your research?
Zooniverse volunteers play a central role in how the whole platform functions. They create the classifications that flow through the systems I work on, and their input is what brings each project to life. When a project is created, volunteers are the ones who generate the data that the platform processes, stores, and makes available to researchers.
My work focuses on the core systems behind this experience. I help maintain and improve the Panoptes API, the tools researchers use to access data, and the pipelines that handle classification processing and machine learning.
Everything depends on volunteers contributing high-quality classifications, and their work is what keeps the entire platform active and meaningful. What I find exciting is seeing how thousands of people from around the world can come together and create data that supports real scientific discovery. My role is to make sure the systems behind that process are fast, reliable, and able to handle the huge amount of participation that Zooniverse projects receive.
While I do not work on individual research outputs, the systems I help build and maintain support all the scientific papers, datasets, and discoveries that come from Zooniverse projects. Without volunteers, and without the infrastructure behind them.
What’s a surprising or fun fact about your research field?
For me, one surprising thing is how global the participation is. A project can receive classifications from people in completely different parts of the world within the same minute. It amazes me how many people contribute to science from their sofa, their commute, or wherever they happen to be.
What first got you interested in research?
I love working on systems that have a direct impact, and the mix of technology, community, and science is what keeps it exciting.
What’s something people might not expect about your job or daily routine?
One thing people might not expect is how often small changes make a big impact. Sometimes a single line of code or a small optimisation can improve performance for millions of classifications. It’s a very technical role, but it’s also rewarding to know that quiet, invisible work can support so many people doing science together.
Outside of work, what do you enjoy doing?
Outside of work, I spend my weekends playing football with friends. I also spend a lot of time playing video games like FIFA and GTA. It’s my favourite way to unwind and switch off. I also enjoy watching documentaries, especially ones about historical events, and I love exploring new technologies just out of curiosity. It keeps things fun and gives me something new to learn all the time.
Is there anything else you’d like to share with our readers?
I’d just like to say that being part of Zooniverse has shown me how powerful community-driven science can be. Every contribution, no matter how small, helps move real research forward. It’s a privilege to help build the systems that make that possible, and I’m excited to see what volunteers and researchers will discover next.
In this edition of Who’s who in the Zoo, meet Adam McMaster, a Research Fellow working at the University of Southampton
Who: Adam McMaster, Research Fellow
Location: University of Southampton, UK
Zooniverse projects: Black Hole Hunters, SuperWASP Variable Stars
What is your research about?
I search archives of astronomical observations, looking for patterns which might be caused by interesting types of star or rare astronomical events. I work with so-called “time series” data, which is where measurements are taken repeatedly over time. In my case, I’m looking at how the brightness of stars changes over anything from days to years. In SuperWASP Variable Stars, we’re looking for certain kinds of repeating variability, such as eclipses and pulsations, in data originally collected by the SuperWASP exoplanet search. In Black Hole Hunters, we’re looking for a type of gravitational microlensing, where a black hole briefly magnifies the light from a star, and we’re currently searching the archives of the TESS exoplanet search, with plans to add data from several other surveys in the near future.
How do Zooniverse volunteers contribute to your research?
The volunteers make our projects possible. We’re looking for the things that get missed by automated searches. Computer algorithms are great at finding a lot of things, but no matter how good they are there will always be things that they miss. Slightly odd looking examples, noisy data, and unexpected things that no one knew to program the computer to find. Only people can find these things, and there is simply too much data to look through ourselves.
In SuperWASP Variable Stars, we’re looking for stars that have been missed in previous searches of the data. The SuperWASP data can be particularly noisy, which can make searching it a challenge. We’ve found that people are really good at separating the noise from the real thing. We’ve written up and published some of the results of this project already, and we publish an interactive database of the results at superwasp.org.
In Black Hole Hunters, the microlensing events we’re looking for are expected to be the hardest ones to spot. Even with really high quality data, we expect the most interesting events to barely stand out against the background noise. That’s what makes a manual search so useful.
What’s a surprising or fun fact about your research field?
The Milky Way is predicted to contain millions of black holes, but we only know about roughly 70 of them. Those were almost all spotted because they’re not really black, at least in X-rays. They’re very bright in X-rays because they’re consuming matter, which heats up as it falls into the black hole. The vast majority of black holes are not expected to be feeding and should truly be black. Those are the ones we’re looking for! We can’t see the black holes themselves, but we should be able to see the effects of their gravity. That’s why we think gravitational microlensing is a good way to find them.
What first got you interested in research?
I have always been interested in science and astronomy for as long as I can remember. I had a telescope as a kid, and I remember going outside to look at the comet Hale-Bopp with my dad. I’m afraid I don’t really remember the first time I thought about actually doing research myself, but I took a rather indirect route to get here. Despite being interested in research (and almost doing a computer science PhD), after university I first worked as a web developer for a few years before eventually finding my way to an astronomy PhD.
Outside of work, what do you enjoy doing?
I’d honestly love just to be able to spend a day sitting and reading a book, but these days my children take up most of my spare time (and energy)! Maybe I’ll be able to do that again in a few years. Also, nothing beats a long walk in the country with the dog.
What are you favourite citizen science projects?
It’s been a long time since it was active, but I always had a soft spot for the SETI Live project here on the Zooniverse. It was obviously unlikely to find anything, but there was something exciting about working on data in real time as it came off of the telescope.
What guidance would you give to other researchers considering creating a citizen research project?
If you’ve never done it before, talk to those of us who have! Especially when it comes to the Zooniverse, everyone is very friendly and happy to help, so there’s no need to try and figure everything out on your own.
All Zooniverse projects are created in English. But many of them are available in different languages – from Armenian and Chinese to Korean and Hungarian. Here is the latest list of translated projects.
The truth is, everyone can become a translator on Zooniverse! But how do you do that? We talked with some of our amazing volunteers who helped various research teams to translate their projects, and here is what we’ve learned.
Zooniverse translators come from all walks of life
Jiří Podhorecký (@trendspotter) lives in Cesky Krumov, a small beautiful town in the Czech Republic. He works in tourism and spends most of his free time supporting various IT projects focusing on ecology, nature conservation and virtual volunteering. Translating the Zooniverse platform and projects into Czech is one of these projects.
InoSenpai (イノ先輩) is a citizen scientist in her 20s in Japan. She studied astronomy in college, but now has another job. She has translated more than 30 Zooniverse space projects into Japanese and she even created a blog in order to introduce them to the Japanese people.
Aarush Naskar (@Sunray_2013) from India is the youngest translator on Zooniverse! He is an amateur astronomer. Story writing, sky watching, reading and coding are his main interests.
Jason Richye is an international student from Indonesia. He is 18 years old and is a business major student. His hobbies are playing basketball, listening to music and watching movies, especially action, comedy and horror.
Louis Verhaeghe (@veragon) is a young French electrical technician passionate about astronomy and astrophysics. As an amateur astronomer, he loves immersing himself in the vastness of the universe and gaining a deeper understanding of what surrounds us. In September 2024, he reached a major milestone: more than 50 projects fully translated into French!
Aarush Naskar (@Sunray_2013) from India is the youngest Zooniverse translator
They translate to help more people discover Zooniverse
Jiří: “I wish that once in the future the whole Zooniverse was available to people in my language. I think that there is a huge and untapped potential in people of all ages, but especially in young people, to build a positive relationship with the world around us and to contribute to it in some way. Citizen science can be an enjoyable and unencumbered contribution to the community that will eventually process this citizen science into real science.”
イノ先輩: “Since Zooniverse is not well known in Japan, I am currently working as a Japanese translator for a number of projects to create a foundation for Japanese users to participate in Zooniverse without feeling any barriers.”
Aarush: ”I was attending a citizen science seminar hosted by the Kolkata Astronomy Club, which my father is the co-founder of, so naturally, I was also a part of it, when I heard about a boy who translated Einstein@Home: Pulsar Seekers to Bengali, so I decided to translate projects to Hindi. I know both Hindi and Bengali, but I am more comfortable with Hindi in terms of writing. It also motivated me that if I translated projects, more people would be able to do them. I also did it thinking I would know more Hindi words.”
Jason: “I’ve always wanted to be part of a research project and contribute in a meaningful way, even in a small role. When I saw one of the translation projects last winter in 2024, I remember feeling genuinely excited. I thought, “This is something I could actually help with.” So when I had the chance to volunteer, I was happy to be involved. Translating made me feel like I was part of something bigger, helping bridge gaps and support the research in a real, practical way.”
Louis (@veragon): “I have been contributing to the Zooniverse platform for almost nine years now. Initially, between 2017 and 2019, I focused exclusively on classifying images and scientific data. In fact, I have surpassed 12,900 classifications! But in late 2019, as my English improved, I asked myself: why not translate projects into French? This would allow more French speakers to get involved in citizen science and contribute to various research initiatives.
It is an immense source of pride for me to contribute, in my own way, to making science more accessible. It is important for me to translate these projects because science should be open to everyone. Many research projects rely on public participation, but the language barrier can be a major obstacle. By translating these projects, I enable thousands of people who are not fluent in English to contribute to scientific research. And the more participants there are, the more high-quality data researchers can gather. It’s a virtuous cycle!”
Louis Verhaeghe (@veragon) translated more than 50 Zooniverse projects into French
Translation expands your knowledge
Aarush: “It is funny that I make a lot (not that many!) mistakes when writing Hindi in real life but I make only some mistakes while translating.”
Jiří: “Fortunately for me, the process is already quite easy, not least because information technology helps us all to get in touch today. The enriching part is always the beginning, when you need to dig into the philosophy of the project and understand how best to use language to express yourself accurately.”
イノ先輩: “I love astronomy, but it has been difficult to love and have knowledge of all of this entire broad field equally. I have always been interested in the classification of light curves of variable stars and how to read radar observation data of meteors, but I had avoided them because they seemed difficult, but I was able to learn them in one week through translation.
The process of grasping all of that content in one’s own brain, reconstructing it in one’s native language, and outputting it is far more effective than simply reading and learning.”
And it makes you realise that your efforts really matter!
イノ先輩: “It is not only the light side of the researcher that we see when we do translations. Unfortunately, we also encounter projects that have been abandoned due to lack of bearers.
Behind this may be issues such as the reality of researchers being chronically overworked and the instability of their posts. But it is not only the beautiful and exciting top part, but also the glimpse into a part of the research project that makes us realize that we are not customers or students, but co-members of the project.”
Jiří: “Citizen science knows no boundaries! You can be all over the world. And it will give you back a strong sense of meaningful help, usefulness, confidence and joy.”
Jason: “You don’t need to be an expert to make a difference.”
Louis: “Together, we can make science more accessible and understandable for everyone. Every contribution matters, and the more of us there are, the greater our impact!”
Jiří Podhorecký (@trendspotter) wishes that once in the future the whole Zooniverse was available to people in Czech.
We asked if they had any advice for aspiring translators
Jason: “Take your time, ask questions, and focus on clarity. It’s a fun way to learn and be part of something meaningful.”
イノ先輩: “Add a bit of playfulness to your project title when you rewrite it in your native language! Mix in parodies and phrases that are unique to the respective cultures of each linguistic area, but only to the extent that they do not detract from the essence of the project. The title of the project may be the reason why some people are interested in it.”
Louis: “If you believe you have a good enough understanding of the languages you’re translating, then go for it! Reach out to various projects that haven’t been translated into your language and offer to translate them. Help us make science more accessible to the entire world!”
Jiří: “Your translation will make it easier for people who may know a foreign language, but whose native language is still closest to them. Without it, they would hardly, if ever, know about the Zooniverse. Oddly enough, language and territorial barriers sometimes serve more as a tool to better divide society. Don’t give up and bring foreign ideas, experience and science to people who need to learn about it in their own language.”
It is easy to start!
Louis: “I started my first translations by directly reaching out to project leaders and offering to translate their projects into French. Over time, I learned how to use Zooniverse’s translation tool, which turned out to be quite intuitive. This approach allowed me to better understand the process and refine my working method.”
Are you interested in volunteering as a Zooniverse translator?
Then you should definitely try it! Here is how:
1. Choose the project you would like to translate
2. Send a message to one of the research team members (privately or on their Talk)*
5. When you are done, let the team know and they will activate your translation to be visible for everyone on Zooniverse!
*An example of a message: “Hello! I’ve enjoyed working on your project (title) and would love to help translate it into (language). Do you think it could be useful? If so, please assign me the Translator role and I will give it a try!”
Are you a researcher looking to set up translations for your project? Please read these instructions. Contact us at contact@zooniverse.org if you need additional support. Please note that the Zooniverse team cannot recommend volunteers translators for your project.
The Vera C. Rubin Observatory is a powerful new facility high in the dry Chilean mountains. Today, on 23 June 2025, for the first time, it is releasing images from its Legacy Survey of Space and Time camera. At 3200 megapixels, this largest camera ever built will allow us to see the universe in a new way. And with Zooniverse, everyone can join and help with discoveries!
Read on to learn more.
NSF-DOE Rubin Trifid and Lagoon Nebulas. Image credit: NSF-DOE Vera C. Rubin Observatory
The “First Look”: The new way of viewing the sky
The first images from the NSF–DOE Vera C Rubin Observatory, our new eye on the sky based high in the Chilean desert, have been released today. The culmination of more than a decade of effort by a team of engineers and scientists, these glimpses of what this new instrument is capable of mark the start of a new way of viewing the sky – and Zooniverse will be a significant part of it. The Observatory’s Legacy Survey of Space and Time (LSST) will start soon, producing data at a scale that means the efforts of volunteers to sort through it and make discoveries will be invaluable.
The images featured in today’s ‘First look’ event were taken by the observatory’s mighty LSSTCam, the instrument which will be the observatory’s workhorse for the next decade and at 3200 megapixels the largest ever built, will manage. They provide a glimpse into the new survey’s ability to catch the changing sky, tracking millions of new asteroids and discovering thousands of supernovae, as well as more exotic and hopefully unexpected events.
NSF-DOE Rubin Virgo cluster 2. Image credit: NSF-DOE Vera C. Rubin Observatory
Vera Rubin Observatory images on Zooniverse
These images are a significant milestone, and all of us at Zooniverse congratulate our partners in the international LSST collaboration on getting here. In the near future – hopefully in just a few days – scientists will get their hands on a first tranche of testing data and, because Zooniverse is a core part of their plans, we should expect to see the first citizen science projects launch shortly thereafter. Once the survey itself gets going later in the year, and when the first of the annual data releases happens next year, we should see a steady flow of Rubin data in Zooniverse projects old or new.
NSF-DOE Rubin Virgo cluster 1. Image credit: NSF-DOE Vera C. Rubin Observatory
Be part of discovery
Whenever astronomers have found a new way of looking at the sky, and thereby opened up a new window on the Universe, we’ve been surprised. A survey of the whole sky, carried out with a telescope that’s the equal of any in the world, and with an immensely sophisticated camera and software pipeline to match, definitely counts. Join us in this first look at the Rubin Observatory sky – and then hang on. We’re all on what looks set to be a fantastic, decade long voyage of discovery.
From June 2025 through January 2026, we will facilitate an online working group of neurodivergent citizen scientists and allies. Together, we will brainstorm, create and publish accessibility guidelines to empower people with all kinds of brains to participate more comfortably in crowdsourced research.
We encourage you to join this new online working group if you:
have experience with online citizen science,
consider yourself neurodivergent or are a neurodiversity ally,
are 18 years old or older,
can communicate in basic written English,
interested in improving accessibility of citizen science for people with mental health and neurological conditions and differences,
can volunteer at least 2 hours of your time (online, flexible) before 16 January 2026.
Please note that, for this call, we welcome participants from all online citizen science projects, not only Zooniverse. All active contributors will be acknowledged in the resulting publication.
No special knowledge is needed. All work is virtual and asynchronous. We are looking forward to working with you all on this important cause!
For more than a decade, I’ve been ending talks by looking forward to the rich data that will soon begin flowing from the Vera Rubin Observatory. The observatory’s magnificent new telescope, nearing its long-awaited first light on a mountaintop in Chile, will conduct a ten year survey of the sky, producing 30 TB of images and maybe ten million alerts a night, covering everything from asteroids to distant galaxies.
The Vera Rubin Observatory Building, ready for action.
The Observatory has – from really early on – seen citizen science, and in particular working with the Zooniverse, as an important part of how they intend to make the most of this firehose of data. We’ve been working hard on things like making data easy to transfer across, designing tools for helping scientists building good projects and more.
All of which is to say I’m very excited – as a Zooniverse person, and as an astronomer – about the opportunities ahead. To allow time for me to concentrate on making the most of it – and in particular, in learning how to find odd stuff alongside Zooniverse volunteers – I’ve decided it’s time for me to step down as Zooniverse Principal Investigator, a position I’ve held since…well, since before the Zooniverse existed.
Giving up the Principal Investigator’s Official Throne will be a hardship, but it’s time.
After 15 or so years, it’s well past time for other people to lead. Laura Trouille from the Adler Planetarium has been my co-PI since 2015, and will be taking over as Principal Investigator. Laura is brilliant, and has been the driving force behind much of what we’ve been doing for a long time. I’m confident in her, and along with her fabulous team, I’m excited to see where she leads this marvellous platform and project. With a growing partnership with NASA, new ideas in how to use Zooniverse in education and reaching new communities, and – of course – new projects launching each week, I genuinely think that we’re in a strong place to keep allowing everyone to participate in science.
In terms of stepping down from this role, I’ll be more Joe Root than Stuart Broad (Note to Americans: This is a cricket reference) – there is a long-standing ‘joke’ that no-one actually leaves the Zooniverse – sticking around the team to serve as Senior Scientist, giving advice where needed and continuing to lead specific projects and efforts. The team in Oxford will work more closely than ever with the rest of the collaboration, and our plans for Rubin and the Zooniverse will be unaffected.
It is, however, strange to be contemplating a change after all this time. I’m immensely proud of the fact that once we stumbled onto the success of the original Galaxy Zoo (a story told in a very reasonably priced book…), we had the imagination not just to build another Galaxy Zoo (which we did – classifications still needed!) but a platform that covers such a wide variety of fields, and through which volunteers have contributed three-quarters of a BILLION classifications. Thanks to the support of all manner of organizations, I’m also very proud that we haven’t had to charge researchers for access to the Zooniverse; the only criteria that have ever mattered has been whether a project will contribute to science and be welcomed by our volunteers.
I’m so grateful to those who have lent their effort, energy and expertise to making a Zooniverse which is grander than I would ever have dared on my own. In particular: Arfon Smith, who created the original Zooniverse with me and took over from me as Director of Citizen Science at Adler, and Lucy Fortson, who has been the best grant-writer and collaborator I could wish for as well as putting up with my stresses more than anyone should have to. I’ll stop here, else I’ll end up listing all of the developers, researchers and volunteers who have made this unique project what it is.
This is a guest post by summer intern Anastasia Unitt.
The study of celestial objects creates a huge amount of data. So much data, that astronomers struggle to make use of it all. The solution? Citizen scientists, who lend their brainpower to analyse and catalogue vast swathes of information. Alex Andersson, a DPhil student at the University of Oxford, has been applying this approach to his field: radio astronomy, through the Zooniverse. I met with him via Zoom to learn about his project detecting rare, potentially explosive events happening far out in space.
Alex’s research uses data collected by a radio telescope located thousands of miles away in South Africa, named MeerKAT. The enormous dishes of the telescope detect radio waves, captured from patches of sky about twice the size of the full Moon. This data is then converted into images, which show the source of the waves, and into light curves, a kind of scatter plot which depicts how the brightness of these objects has changed over time. This information was initially collected for a different project, so Alex is exploiting the remaining information in the background- or, as he calls it: “squeezing science out of the rest of the picture.” The goal: to identify transient sources in the images, things that are changing, disappearing and appearing.
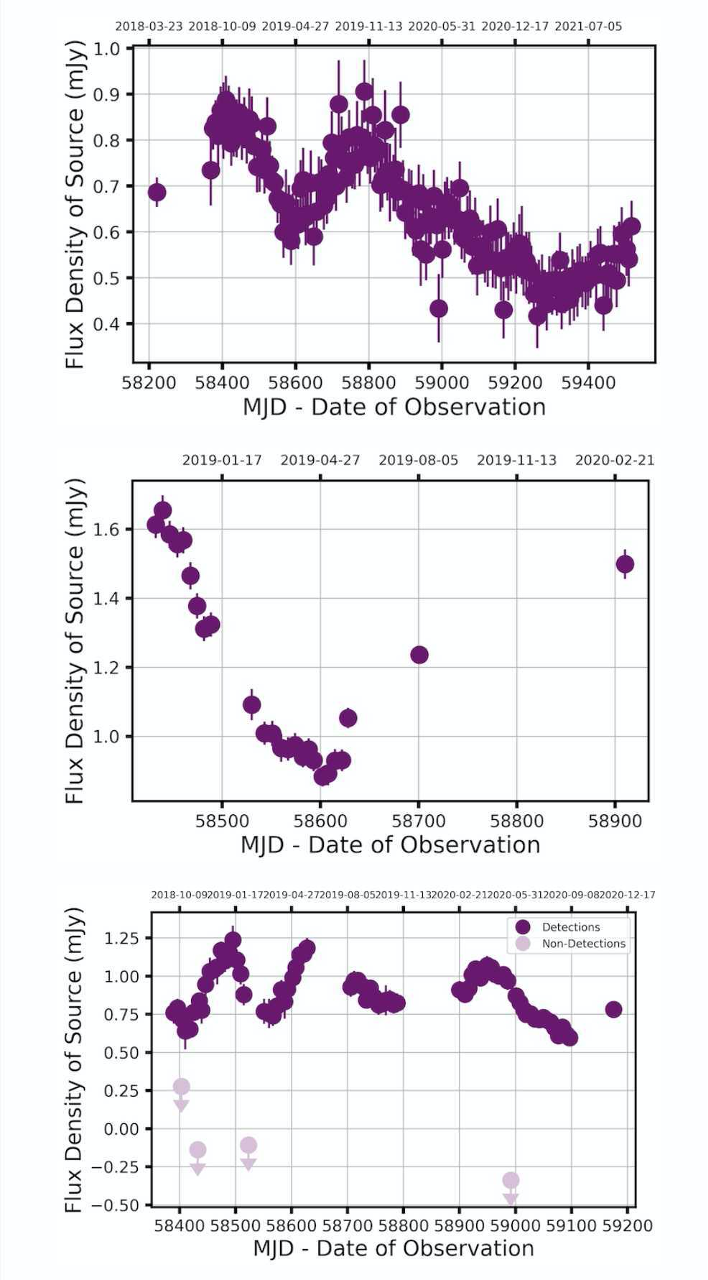
Historically, relatively few of these transients have been identified, but the many extra pairs of eyes contributed by citizen scientists has changed the game. The volume of data analysed can be much larger, the process far faster. Alex is clearly both proud of and extremely grateful to his flock of amateur astronomers. “My scientists are able to find things that using traditional methods we just wouldn’t have been able to find, [things] we would have missed.” The project is ongoing, but his favourite finding so far took the form of a “blip” his citizen scientists noticed in just two of the images (out of thousands). Alex explains: “We followed it up and it turns out it’s this star that’s 10 times further away than our nearest stellar neighbor, and it’s flaring. No one’s ever seen it with a radio telescope before.” His excitement is obvious, and justified. This is just one of many findings that may be previously unidentified stars, or even other kinds of celestial objects such as black holes. There’s still so much to find out, the possibilities are almost endless.
A range of light curve shapes spotted by Zooniverse citizen scientists performing classifications for Bursts from Space: MeerKAT
Unfortunately, research comes with its fair share of frustrating moments along with the successes. For Alex, it’s the process of preparing the data for analysis which has proved the most irksome. “Sometimes there’s bits in the process that take a long time, particularly messing with code. There can be so much effort that went into this one little bit, that even if you did put it in a paper is only one sentence.” These behind-the-scenes struggles are essential to make the data presentable to the citizen scientists in the first place, as well as to deal with the thousands of responses which come out the other side. He assures me it’s all worth it in the end.
As to where this research is headed next, Alex says the prospects are very exciting. Now they have a large bank of images that have been analysed by the citizen scientists, he can apply this information to train machine learning algorithms to perform similar detection of interesting transient sources. This next step will allow him to see “how we can harness these new techniques to apply them to radio astronomy – which again, is a completely novel thing.”
Alex is clearly looking forward to these further leaps into the unknown. “The PhD has been a real journey into lots of things that I don’t know, which is exciting. That’s really fun in and of itself.” However, when I ask him what his favourite part of this research has been so far, it isn’t the science. It’s the citizen scientists. He interacts with them directly through chat boards on the Zooniverse site, discussing findings and answering questions. Alex describes their enthusiasm as infectious – “We’re all excited about this unknown frontier together, and that has been really, really lovely.” He’s already busy preparing more data for the volunteers to examine, and who knows what they might find; they still have plenty of sky to explore.
The Zooniverse team in Oxford, UK, is looking for a web developer intern to join us in summer 2022. If you’re looking to learn how to build websites and apps with a team of friendly developers, or if you just want an opportunity to flex your extant coding skills in an environment that loves scientific curiosity, then come have some tea with us!
The team here in the Zooniverse want to welcome more folks into the world of software development, and in turn, we want to learn from the unique ideas and experiences you can share.
The world's largest and most popular platform for people-powered research. This research is made possible by volunteers—millions of people around the world who come together to assist professional researchers.