This April, Citizen Science Month invites people everywhere to take part in something special: 2.50 Million Acts of Science in celebration of America’s 250th birthday.
SciStarter weekly online events
In addition to hundreds of projects and events scheduled throughout the month, our friends at SciStarter are organising weekly, online events where volunteers from around the world will work on the same project at the same time, guided by the scientists leading the research.
All Zooniverse projects are created in English. But many of them are available in different languages – from Armenian and Chinese to Korean and Hungarian. Here is the latest list of translated projects.
The truth is, everyone can become a translator on Zooniverse! But how do you do that? We talked with some of our amazing volunteers who helped various research teams to translate their projects, and here is what we’ve learned.
Zooniverse translators come from all walks of life
Jiří Podhorecký (@trendspotter) lives in Cesky Krumov, a small beautiful town in the Czech Republic. He works in tourism and spends most of his free time supporting various IT projects focusing on ecology, nature conservation and virtual volunteering. Translating the Zooniverse platform and projects into Czech is one of these projects.
InoSenpai (イノ先輩) is a citizen scientist in her 20s in Japan. She studied astronomy in college, but now has another job. She has translated more than 30 Zooniverse space projects into Japanese and she even created a blog in order to introduce them to the Japanese people.
Aarush Naskar (@Sunray_2013) from India is the youngest translator on Zooniverse! He is an amateur astronomer. Story writing, sky watching, reading and coding are his main interests.
Jason Richye is an international student from Indonesia. He is 18 years old and is a business major student. His hobbies are playing basketball, listening to music and watching movies, especially action, comedy and horror.
Louis Verhaeghe (@veragon) is a young French electrical technician passionate about astronomy and astrophysics. As an amateur astronomer, he loves immersing himself in the vastness of the universe and gaining a deeper understanding of what surrounds us. In September 2024, he reached a major milestone: more than 50 projects fully translated into French!
Aarush Naskar (@Sunray_2013) from India is the youngest Zooniverse translator
They translate to help more people discover Zooniverse
Jiří: “I wish that once in the future the whole Zooniverse was available to people in my language. I think that there is a huge and untapped potential in people of all ages, but especially in young people, to build a positive relationship with the world around us and to contribute to it in some way. Citizen science can be an enjoyable and unencumbered contribution to the community that will eventually process this citizen science into real science.”
イノ先輩: “Since Zooniverse is not well known in Japan, I am currently working as a Japanese translator for a number of projects to create a foundation for Japanese users to participate in Zooniverse without feeling any barriers.”
Aarush: ”I was attending a citizen science seminar hosted by the Kolkata Astronomy Club, which my father is the co-founder of, so naturally, I was also a part of it, when I heard about a boy who translated Einstein@Home: Pulsar Seekers to Bengali, so I decided to translate projects to Hindi. I know both Hindi and Bengali, but I am more comfortable with Hindi in terms of writing. It also motivated me that if I translated projects, more people would be able to do them. I also did it thinking I would know more Hindi words.”
Jason: “I’ve always wanted to be part of a research project and contribute in a meaningful way, even in a small role. When I saw one of the translation projects last winter in 2024, I remember feeling genuinely excited. I thought, “This is something I could actually help with.” So when I had the chance to volunteer, I was happy to be involved. Translating made me feel like I was part of something bigger, helping bridge gaps and support the research in a real, practical way.”
Louis (@veragon): “I have been contributing to the Zooniverse platform for almost nine years now. Initially, between 2017 and 2019, I focused exclusively on classifying images and scientific data. In fact, I have surpassed 12,900 classifications! But in late 2019, as my English improved, I asked myself: why not translate projects into French? This would allow more French speakers to get involved in citizen science and contribute to various research initiatives.
It is an immense source of pride for me to contribute, in my own way, to making science more accessible. It is important for me to translate these projects because science should be open to everyone. Many research projects rely on public participation, but the language barrier can be a major obstacle. By translating these projects, I enable thousands of people who are not fluent in English to contribute to scientific research. And the more participants there are, the more high-quality data researchers can gather. It’s a virtuous cycle!”
Louis Verhaeghe (@veragon) translated more than 50 Zooniverse projects into French
Translation expands your knowledge
Aarush: “It is funny that I make a lot (not that many!) mistakes when writing Hindi in real life but I make only some mistakes while translating.”
Jiří: “Fortunately for me, the process is already quite easy, not least because information technology helps us all to get in touch today. The enriching part is always the beginning, when you need to dig into the philosophy of the project and understand how best to use language to express yourself accurately.”
イノ先輩: “I love astronomy, but it has been difficult to love and have knowledge of all of this entire broad field equally. I have always been interested in the classification of light curves of variable stars and how to read radar observation data of meteors, but I had avoided them because they seemed difficult, but I was able to learn them in one week through translation.
The process of grasping all of that content in one’s own brain, reconstructing it in one’s native language, and outputting it is far more effective than simply reading and learning.”
And it makes you realise that your efforts really matter!
イノ先輩: “It is not only the light side of the researcher that we see when we do translations. Unfortunately, we also encounter projects that have been abandoned due to lack of bearers.
Behind this may be issues such as the reality of researchers being chronically overworked and the instability of their posts. But it is not only the beautiful and exciting top part, but also the glimpse into a part of the research project that makes us realize that we are not customers or students, but co-members of the project.”
Jiří: “Citizen science knows no boundaries! You can be all over the world. And it will give you back a strong sense of meaningful help, usefulness, confidence and joy.”
Jason: “You don’t need to be an expert to make a difference.”
Louis: “Together, we can make science more accessible and understandable for everyone. Every contribution matters, and the more of us there are, the greater our impact!”
Jiří Podhorecký (@trendspotter) wishes that once in the future the whole Zooniverse was available to people in Czech.
We asked if they had any advice for aspiring translators
Jason: “Take your time, ask questions, and focus on clarity. It’s a fun way to learn and be part of something meaningful.”
イノ先輩: “Add a bit of playfulness to your project title when you rewrite it in your native language! Mix in parodies and phrases that are unique to the respective cultures of each linguistic area, but only to the extent that they do not detract from the essence of the project. The title of the project may be the reason why some people are interested in it.”
Louis: “If you believe you have a good enough understanding of the languages you’re translating, then go for it! Reach out to various projects that haven’t been translated into your language and offer to translate them. Help us make science more accessible to the entire world!”
Jiří: “Your translation will make it easier for people who may know a foreign language, but whose native language is still closest to them. Without it, they would hardly, if ever, know about the Zooniverse. Oddly enough, language and territorial barriers sometimes serve more as a tool to better divide society. Don’t give up and bring foreign ideas, experience and science to people who need to learn about it in their own language.”
It is easy to start!
Louis: “I started my first translations by directly reaching out to project leaders and offering to translate their projects into French. Over time, I learned how to use Zooniverse’s translation tool, which turned out to be quite intuitive. This approach allowed me to better understand the process and refine my working method.”
Are you interested in volunteering as a Zooniverse translator?
Then you should definitely try it! Here is how:
1. Choose the project you would like to translate
2. Send a message to one of the research team members (privately or on their Talk)*
5. When you are done, let the team know and they will activate your translation to be visible for everyone on Zooniverse!
*An example of a message: “Hello! I’ve enjoyed working on your project (title) and would love to help translate it into (language). Do you think it could be useful? If so, please assign me the Translator role and I will give it a try!”
Are you a researcher looking to set up translations for your project? Please read these instructions. Contact us at contact@zooniverse.org if you need additional support. Please note that the Zooniverse team cannot recommend volunteers translators for your project.
As the U.S. Congress deliberates on next year’s budget, proposed 50% cuts to agencies like NASA and the National Science Foundation (NSF), and the deeply concerning layoffs at the Institute of Museum and Library Services (IMLS), the National Endowment for the Humanities (NEH), and the National Endowment for the Arts (NEA), jeopardize the work of organizations like Zooniverse that rely on federal funding.
Although Zooniverse is an international collaboration, with core institutional partners in both the U.S. and the UK, this post focuses on the vital role that U.S. federal support has played in enabling our impact. As these funding decisions are made, we wanted to share how essential this support has been to Zooniverse’s impact on research and public engagement.
From the start, federal grants have been a cornerstone of Zooniverse’s ability to innovate and scale. A seed grant from the NSF in 2009 helped us explore the integration of machine learning with participatory science, work that laid the foundation for Zooniverse to become one of the world’s most sophisticated platforms for AI-enhanced crowdsourced research. A grant from IMLS advanced our Digital Humanities efforts, and a follow-on NEH grant enabled us to build critical infrastructure, like our ALICE system, for reviewing and editing transcriptions across humanities projects. Most recently, support from the National Institutes of Health (NIH) enabled a new initiative to render three-dimensional subjects within Zooniverse, expanding the platform’s capabilities to advance biomedical research.
Federal support has also been instrumental in strengthening Zooniverse’s public impacts, from an NSF Improving Undergraduate STEM Education (IUSE) grant that led to the creation of classroom.zooniverse.org to an NSF Advancing Informal STEM Learning (AISL) grant that launched a multi-person Galaxy Zoo touch table exhibit at the Adler Planetarium in Chicago. This hands-on experience reaches tens of thousands of visitors each year and often serves as the first entry point for children and their families into the world of participatory science.
Crucially, these federal grants don’t just fund abstract ideas or technologies, they fund people. Federal support helps pay the salaries of the software engineers, researchers, and participatory science professionals who build and maintain the Zooniverse platform, collaborate with research teams, and support our community of nearly 3 million volunteers.
Our current NASA grant, for example, enables over two dozen NASA research teams to unlock their datasets through Zooniverse and funds core platform maintenance efforts, an area of support notoriously difficult to secure. Our NASA grant also allowed us to respond directly to community needs through the implementation of new Group Engagement features and student service hours support, among the most requested tools from educators, classrooms, museums, and others using Zooniverse in group settings around the world.
Today, Zooniverse is part of the core infrastructure of research and scholarship. We partner with more than 150 research institutions and nearly 3 million volunteers worldwide. Our platform is a critical tool in the modern researcher’s toolkit, including in fields relying on human-in-the-loop AI methods to analyze vast datasets. At the same time, we are a trusted platform for public engagement, helping build confidence in science and fostering a sense of shared purpose across disciplines, borders, and backgrounds.
Like many research and public engagement organizations, Zooniverse has deeply benefitted from federal grant support. We felt it was important to share with our communities just how vital this support has been. Much of what we’ve built — our infrastructure, partnerships, and public-facing tools — would not have been possible without it. Continued federal investment remains critical to sustaining and growing this work.
I hadn’t even walked in the door yet, and walking up to my first day working at Adler Planetarium/Zooniverse was already one of the coolest places I’ve ever worked. The bus dropped me off, and because of the schedule, I arrived about 15 minutes early. I was extremely eager to begin this summer but decided to take a moment and sit on a bench close by to take in the beautiful view of Lake Michigan and the Chicago skyline. I had no idea what the summer was about to hold.
Why science communication?
I took a long, winding road to get to Adler/Zooniverse this summer, but the timing was perfect. I have always prioritized public engagement and science communication in my work, and it began in undergrad, where I was a tour guide and a teaching assistant. After graduation, I started working as a high school math teacher and presenting live science shows at the planetarium on the weekends. This combination of positions taught me how to do the seemingly impossible – get high schoolers excited about math. I brought my science communication training and the use of demos from the planetarium into the classroom to create an engaging environment. This led me to work as an instructor at a community college where I faced a different challenge – working with many varying backgrounds because most students came to my night class after working a long day job. I was teaching a math course with a supplemental lab where my focus was to get my students to build growth mindset skills, empowering them to succeed in my class. All these experiences led me to return to graduate school, where I continued to prioritize outreach, and I began the NASA-Zooniverse participatory science project Dark Energy Explorers. As project lead, this challenged me differently, acting as a liaison between highly specialized researchers and the general public.
While waiting to enter the building for the first time I took a walk around the whole planetarium only to be surprised with a glimpse of the Doane Observatory. Here, I paused for a first day picture to send to my family!
I say all of this because, before this summer, I felt like I was building all these skills out of sync and never in tandem. This summer at Adler/Zooniverse was the first time I truly had the opportunity to intertwine all these skills I’ve built over the years in one position while also gaining new skills from the experts here. I came to Adler/Zooniverse through the NSF Non-Academic Research Internships for Graduate Students (INTERN) for graduate students looking to grow a complementary skill set outside of an academic setting. Being a Zooniverse project lead and someone with an informal education background, coming to Adler/Zooniverse to focus on science communication skills was a perfect fit. Zooniverse PI, Laura Trouille, was my main mentor throughout the experience.
This summer, all of the projects I took on fell into the following modes of communication– written (articles, storybooks), spoken (talks, explanations), and visual (video, graphics, social media).
Networking and gaining skills
My first week, I was thrown right into filming for Adler’s social media’s ‘Ask an Astronomer’ segment. This might have been some of the most fun I had. I worked with other Adler astronomers, Mike Zevin and Geza Gyuk, to write answers to some of the most frequently asked questions in astronomy with an extra challenge of it could only be one minute long. We filmed with the marketing team Bella, Audrey, and Colleen, seen here, where we spent most of the filming perfecting a swivel chair spin. In addition to these videos for Adler social media, I also worked on a few posts for NASA Citizen Science and explored the Zooniverse social media revamp with Alisa Apreleva at Oxford University.
Continuing to work with Mike Zevin, I took on a project to develop a new way to incorporate Zooniverse into the Astronomy Conversations program at Adler. Astronomy Conversations is a program that hosts researchers and visiting scientists to engage with museum guests about their research. We discovered a way to use the space visualization lab to project a Zooniverse project and then use a project as a take-home activity for visitors. For instance, if a guest was particularly interested in asteroids, they classify on Asteroid Hunters in the SVL and then continue learning at home on their own on Zooniverse.
Before this summer, I had no video editing skills and barely knew how to use iMovie. With a tutorial from Laura, and design help from Zooniverse Designer Sean Miller, I put together a video for educators using the new Zooniverse Groups features. This video helps educators of all kinds (teachers, camp counselors, museum leads, librarians, etc.) to feel comfortable and confident using the new features in their education setting.
Becoming a ‘consultant astronomer’
My most novel experience was working with Adam Fotos (professor at Chicago State University) as a ‘consultant astronomer’ (I just made that title up). Adam contacted the team for advice for his new children’s book, Growing to the Moon. He wanted to ensure some of the book was rooted in actual astronomy concepts while still maintaining a fantastical, fun story. I agreed to help him tackle this task and then attended one of the planetarium shows at Adler, Imagine the Moon. Following this, we discussed incorporating those ideas into the plot line and how it could appeal to kids of varying ages. Look out for his book to be published soon!
Meeting with Adam to consult for the storybook, we watched the Imagine the Moon planetarium show amongst many other excited Adler visitors.
Communicating science accessibly
One of my most significant points of personal growth this summer has been in my science writing. My love for writing has taken a new perspective as I’ve been able to learn how to communicate my research on very niche astronomy topics, like dark energy or machine learning, for the general public. I was able to share part of my journey of choosing astronomy in the ‘working life’ section of Science Magazine, which culminated with my presentation of three posters and a talk at the International Astronomical Union Meeting in Cape Town, South Africa!
In addition to all the inspirational things that happened at work, I witnessed the auroras in the middle of Chicago off of North Ave pier, reflecting off Lake Michigan!
Place to learn and grow
After one of the most fullfilling summers of my life, I can reflect back to that first day after I walked through the door and Laura began showing me around the building. Along the way we ran into Adler President, Michelle Larson. The three of us had a lovely chat about how excited we were about what the summer would hold and how quickly it would go by. That was an understatement. In hindsight, that conversation was representative of the next few months. I witnessed the exceptional work environment these ladies (and the whole team!) have created here. They have made Adler and Zooniverse places where people come to learn and grow, not only as science enthusiasts but as people. In my experience, this is very rare to find. From the projects, to the people, to the place of Chicago, I spent this summer learning, laughing, and growing as a science communicator and a human. I’m grateful for the opportunity to be a part of this community through the NSF INTERN program, and I hope to continue collaborating with the Adler/Zooniverse team into the future!
The guest post was written by Lindsay R. House, a Science Communicator with Adler Planetarium and Zooniverse in Chicago from April to August 2024. Lindsay is the project lead for the NASA-Zooniverse participatory science project, Dark Energy Explorers. Lindsay spent this time at Adler on a supplemental National Science Foundation INTERN grant, which allowed her to gain valuable science communication skills that complement her studies as a 5th-year Astronomy Ph.D. student at the University of Texas Austin.
Over the years, one of the most common requests from educators has been for tools to support group engagement in Zooniverse and better tell your story of collective impact. We’re so grateful for a grant from NASA enabling us to build these new tools to meet those needs.
Whether you’re a library or museum educator, a camp counselor, or a classroom teacher, read on to discover how Zooniverse can enhance your educational goals.
Zooniverse is the world’s largest platform for people-powered research, with millions of participants and dozens of active projects across various disciplines. By using Zooniverse, you join a global network of educators offering students often their first opportunity to engage in real research. From classifying galaxies and tagging penguins to transcribing historic documents and marking the structure of cells for cancer research, Zooniverse projects span a wide array of research fields.
For a list of curricular resources for educators, including lesson plans, instructor guides, and more, check out zooniverse.org/get-involved/education.
Tracking Individual and Collective Impact
Zooniverse offers easy ways to track both individual and collective impact, making it easy to use in educational settings. You can assign tasks, motivate participation, set up friendly competitions between classes, and more.
Personal Stats
When logged into Zooniverse, each individual sees their own stats, including classification counts and hours spent. A valuable feature for fulfilling service hour requirements is the ability to generate a signed volunteer certificate.
Group Stats
Groups in Zooniverse can view their collective impact, set shared goals, and celebrate milestones. These tools empower educators to engage students in new ways.
Step 1: Create Your Group
Go to zooniverse.org, sign in, and scroll down to ‘My Groups’. Click ‘Create New Group.’ Name your group appropriately, such as “Hammond’s 4th Period Biology” or “Davis County Public Library.”
As the admin, you can decide if the group stats page will be publicly viewable or only accessible to group members. Additionally, you can choose whether to display individual stats or only aggregate results. For example, if your group stats page is public, you can set it so that only you can see individual stats, or you can allow other group members or everyone to see them. Through the admin pop-up, you can update your group settings or remove group members at any time.
For additional Group details/features, see this blog post.
Step 2: Invite Participants to Join Your Group
Have your students or program participants create a Zooniverse account by clicking ‘Register’ in the upper-right corner of zooniverse.org. To invite them to join your group, click the ‘Copy Join Link’ on your group’s page and share it via email or other preferred means, such as creating a QR code.
Once they click the join link, all classifications they do on any Zooniverse project will be included in your group stats page, contributing to your group’s collective impact.
Step 3: View/Share Your Group Stats
When viewing your group stats page, you can use the drop-down options on the upper-right of the stats bar chart to filter to a specific time period and/or project of interest. Another helpful feature is the ‘See detailed stats’ option, where you can view all group contributors’ stats and generate a .CSV file for further analysis. A future feature will be the ability to filter to specific time periods within this detailed stats page.
Members of your group will also be able to view the group stats page. Depending on the choices you’ve made in the admin settings, group members will either be able to only view the aggregate stats OR they’ll be able to view both the aggregate and individual stats.
If you’ve set your group visibility settings to ‘public’, you’ll have the ‘Share Group’ option at the top of your group’s stats page. Clicking ‘Share group’ will copy a link to the public-facing view of your group’s stats page. This is different from a ‘Join Link’. Anyone with the ‘Share Group’ link will simply be able to view the group’s stats, but will not be added as a member of the group.
Celebrating Milestones
A few Zooniverse project teams have created short thank you videos, which are great rewards to share with your students after reaching a collective milestone.
Example: STEM Club at a Public Library
Imagine you lead a STEM club at your local public library. You create a group, set the settings to public but only for aggregate results (i.e, not showing individual stats publicly), copy the join link, and share it with your group members. You set a classification challenge for the week, share recommended projects (see zooniverse.org/projects for the full list), and encourage free choice. Throughout the week, you update your group on progress toward your goal. At your next meeting, you celebrate reaching the goal with a thank you video and highlight top contributors with special rewards. Then, you set the next week’s challenge to keep the momentum going.
Other Use Cases
Friendly competition among class periods
Extra credit opportunities for your students
Extension activity after a museum field trip experience
Summer camp group tracking independent research time
Share your Stories of Impact with Us
We’d love to hear about your experience and share your stories of impact with the broader Zooniverse community to spark ideas and inspiration in others. See this Daily Zooniverse post as an example. Email us at contact@zooniverse.org with your stories!
Get in Touch
If you have questions or need advice, join the conversation in our dedicated Talk discussion forum around Education and the Zooniverse or email us at contact@zooniverse.org.
On behalf of Zooniverse, we are incredibly grateful that you choose to use participatory science in your educational programs and hope to continue fostering this innovative community of educators around the world.
Thank you for including Zooniverse in your educational efforts!
This guest post was written by the Davy Notebooks Project research team. It was updated on 21 October 2024 to include a link to the published transcription site.
The Davy Notebooks Project first launched as a pilot project in 2019. After securing additional funding and three months of testing and revision, the project re-launched in June 2021 in its current, ‘full’ iteration. And now it is drawing to a close.
Since April 2021, 11,991 pages of Davy’s manuscript notebooks have been transcribed – this, of course, is a major achievement. Adding the 1,130 pages transcribed during our pilot project, which launched in April 2019, brings the total up to 13,121 pages. Including Zooniverse beta test periods (during which time relatively few pages were made available to transcribe), this was achieved in a period of forty-one months; discounting beta test periods brings the total down to thirty-six months. At the time of writing, with the transcription of Davy’s 129 notebooks now complete, the Davy Notebooks Project has 3,649 volunteers from all over the world. 505 volunteers transcribed during our pilot project, so the full project attracted 3,144 transcribers.
The transition from the pilot build to the developed full project that, at its peak, was collecting up to 6,675 individual classifications per month, has been a steady learning experience. Samantha Blickhan’s article (co-authored by other members of the project team) in our special issue of Notes and Records of the Royal Society, ‘The Benefits of “Slow” Development: Towards a Best Practice for Sustainable Technical Infrastructure Through the Davy Notebooks Project’, charts the Davy Notebooks Project’s development, and makes a convincing case for the type of ‘slow’ development – or gradual improvement in response to feedback – approach that the project has taken.
While new notebooks were being released and transcribed on Zooniverse, the project’s editorial team were reviewing and editing the submitted transcriptions through Zooniverse’s ALICE (Aggregated Line Inspector and Collaborative Editor) app. The team were also engaging, daily, with our transcriber community on the project’s Talk boards – discussing particularly tricky or interesting passages in recently transcribed pages, sharing information and insights on the material being transcribed, and creating a repository of useful research that has been valuable in tracing connections throughout Davy’s textual corpus as a whole and in writing explanatory notes for the transcriptions. The current number of individual notes (repeated throughout the edition as necessary) stands at approximately 4,500.
Running a successful online crowdsourcing project requires effective two-way communication between the project team and the volunteer community. A series of ‘off Zooniverse’ volunteer-focused events offered the opportunity to engage with our volunteers, and – importantly – a venue to thank them for their continued, frequently excellent efforts in transcribing and interpreting Davy’s notebooks. Conference panels at large UK conferences with international representation (the British Society for Literature and Science conferences in 2022 and 2023, the British Association for Romantic Studies conference, jointly held with the North American Society for the Study of Romanticism, in 2022) enabled the project team to share their research-in-progress with the academic community, and our own conference, ‘Science and/or Poetry: Interdisciplinarity in Notebooks’, held at Lancaster University in July 2023, brought together scholars working on a diverse range of notebooks and other related manuscript materials to share our most recent insights and findings. Our monthly project team reading group, superbly organised by Sara Cole over several years, helped us to think about the organisation of Davy’s notebook collection as a whole, and created many a new research lead. Our travelling exhibition, which stopped at the Royal Institution, Northumberland County Hall, and Wordsworth Grasmere, has created new interest in Davy and his notebooks, and presented some of the key research findings of the project. All of these events fed directly into maintaining the momentum of the Davy Notebooks Project.
We are now moving towards the publication of the free-to-access digital edition of Davy’s whole notebook corpus that has been our goal since the start. Our digital edition will be hosted on the Lancaster Digital Collections platform, which is based on the well-established Cambridge Digital Library platform. View the Davy Notebooks transcription collection here: https://digitalcollections.lancaster.ac.uk/collections/davy/1.
Thankfully, we have benefited from the continued involvement, post-transcription, of a core of volunteer transcribers, who have taken on new responsibilities in assisting with the final editing of the notebooks; special thanks go to David Hardy (@deehar) and Thomas Schmidt (@plphy), who have helped to improve our transcriptions and notes in significant measure. We have also benefited at various points in the project from additional research assistance, from our UCL STS Summer Studentship project interns (Alexander Theo Giesen, Mandy Huynh, Stella Liu, Clara Ng, and Shreya Rana), from specialists in early nineteenth-century mathematics (Brigitte Stenhouse and Nicolas Michel), and from students and postgraduates in the Department of English Literature and Creative Writing at Lancaster University (Emma Hansen, Lee Hansen, Rebekah Musk, Frank Pearson, and Rebecca Spence), for which we are very grateful.
Work continues behind the scenes on finalising the transcriptions on LDC, and on the preparation of our forthcoming special issue of Notes and Records of the Royal Society, which is due to be published at the end of the year. Our digital edition will be officially launched at Lancaster Litfest on Saturday 19 October 2024. This will give us another opportunity to thank the thousands of volunteers who have made this work possible.
Truly, we could not have made the important advances in Davy scholarship that we have made since 2019 without every one of our volunteers, who gave freely and generously of their time and knowledge, and who hopefully enjoyed playing such a key role in a large research project – this is not only a social edition of Davy’s notebooks, but also, in large measure, their edition. Thank you all.
Guest post from Eilidh O’Brien, Staff Scientist, Whales of Iceland Museum
Appropriately located in Reykjavík’s harbour district, Whales of Iceland is the largest museum dedicated to cetaceans in Europe. Much of the space inside is dedicated to life-sized models of the 23 species of whales, dolphins and porpoises that have been sighted in the waters around Iceland throughout history, some very common while others are very rare. When the museum was founded these models were the main focus of the exhibition: a chance for visitors to experience the true size of these gigantic marine animals, and to learn a little about each of the species on display. However, this focus is now evolving and Zooniverse is set to play an important part.
Iceland is a hotspot for cetaceans – and so, also for cetacean researchers! Some remarkable discoveries have been made here in the last decade, from the first recordings of humpback whales singing in their feeding grounds over winter, to the unusual antagonistic interactions between killer whales and long-finned pilot whales. We want to highlight this at Whales of Iceland so that our museum is not just a place to learn about cetaceans themselves, but also how scientists study these fascinating and complex animals, what this research has uncovered, and all the things that we still do not know!
In addition to learning about the research happening here in Iceland, we want to give visitors the opportunity to take part in some real scientific projects. So, thanks to Zooniverse, our newest exhibit will include a citizen science station where anyone can have a shot at being a scientist! We will feature a range of Zooniverse projects for visitors to choose from, giving them a variety of different marine mammal species and different aspects of wildlife ecology to learn about.
Our aim is to make Whales of Iceland a more interactive and thought-provoking experience. We hope that our museum will continue to offer visitors the chance to marvel at the size and beauty of these wonderful creatures, but also to engage with the natural world in ways they may not have before, and to feel that they have not just learned, but discovered.
This collaboration is still in its early stages. With the green light from Zooniverse Co-PI Dr. Laura Trouille, we have already launched a scaled-down version of what we hope the final exhibit will be, and it has been a really promising success! Museums provide a perfect platform for citizen science; we are a small museum relatively speaking, but our footfall in peak season can be more than 400 people in a day. That’s a lot of potential citizen scientists! In ecology, we would call this a mutualistic symbiosis – or, in other words, everyone wins! Our museum guests can provide valuable contributions to scientific projects all over the world, while at the same time gaining first-hand insight into the life of a whale researcher.
We are so excited to develop and expand our collaboration with Zooniverse, as well as other citizen science initiatives. Our finished research exhibit will be unveiled very soon – watch this space!
By Tasnova, Guest Writer and Adler Zooniverse Summer ’22 Teen Intern
This summer, I worked as an intern for the Adler Planetarium in Chicago, alongside Lola Fash and Dylan. As a group, we carried out Zooniverse projects and interviews with the researchers leading them. In this blog post, I will share about my experience with the main project that I took part in: Transcribe Colored Conventions.
In July 2022 I interviewed Dr. Jim Casey and Justin Smith, two of the research leads for the Colored Conventions project with Zooniverse. Dr. Casey is an assistant research professor of African American Studies at Penn State University, managing director of the Center for Black Digital Research, and co-founder for the Colored Conventions project. Justin Smith is a Ph.D. candidate in English and African American studies at Penn State and a member of the Douglass Day team.
Before I dig into what the Colored Conventions were, I’d like to share my own experience while working on these projects. I chose to focus on Transcribe Colored Convention because I am a huge history lover. I want to learn everything; learning feeds my curiosity. I was really excited to learn about the Colored Conventions since they are often neglected in textbooks; my school never taught me about the Colored Conventions. It was my first time learning anything about the Colored Conventions. I was so excited to get to interview the amazing people leading the Zooniverse project to transcribe documents related to the Colored Conventions.
The Colored Conventions were events that took place during the nineteenth century and spread across 34 states. In these Conventions, the participants talked about how they could get access to voting rights, education, labor, and business.
However, despite how important they were, no one really talks about the Colored Conventions today. It is incredibly sad for me to see this important part of our history being neglected.
Another interesting aspect about the Colored Conventions that I learned about through interviewing the team is that the documents related to the Conventions were very male dominated. What this means is that while men’s efforts were well documented in the Conventions’ archive, women’s efforts were not. For example, of the names initially identified and highlighted in the documents, 98% belong to men.
An early researcher who recognized women’s contributions to the Colored Conventions is Dr. Psyche William Foresham, a University of Maryland professor who wrote the essay “What Did They Eat? Where Did They Stay?” In the essay she talked about how women organized restaurants and boarding houses for the people who traveled from other states to join the Convention meeting. They also financially supported them. The essay was eye opening for other researchers, and prompted them to read the Conventions’ documents more carefully to find references to women that might have been overlooked. As a result of these efforts, they found more references to women in the Convention documents.
Zooniverse volunteers also helped transcribe the Colored Convention documents, further unlocking the data for the researchers. The researchers were thrilled to see so many people actually participating in transcribing the documents and caring deeply about the project. The volunteers transcription efforts also uncovered additional evidence of references to women’s efforts in the Colored Convention documents. In my own journey learning about this project, I was happily surprised to see that so many people participated in transcribing the documents and cared about this piece of history that was neglected for so long.
Here are some clips from the full recording of my interview with Dr. Jim Casey and Justin Smith.
A few final thoughts: When I was interviewing the researchers, I loved seeing how passionate they were. It feels rare to talk with people who are passionate about their work. If I see someone who is really passionate about their work and the effort they put in, it’s incredibly motivating. I hope to feel the same in my career.
Colored Convention Project team helping the volunteers during the Transcribe-a-Thon. Credit: Dr. Jim Casey
During my interview, I was nervous in the beginning because this was my first time interviewing a researcher, or anyone. My hands and feet were cold. I tried to calm myself down so I wouldn’t stutter. I think I did a good job interviewing them. My mentor, Sean (who is the Zooniverse designer at Adler), helped me a lot in preparing for the interview. He helped me see that the pressure is not on me as an interviewer; instead, the pressure is on the interviewees because they need to answer the questions. I think that really helped me to calm down because I kept saying to myself that “the pressure is on them, not me.” And my interviewees were such nice people too! I was proud of myself for how I carried out the interview.
Last, but not least, thank you to my teammates Dylan and Lola Fash for helping me out with my summary, video editing, and my blog.
These are my Zooniverse intern colleagues. They helped me with every single challenge in my internship. Photo credit: Tasnova]
By Dylan, Guest Writer and Adler Zooniverse Summer ’22 Teen Intern
Every once in a while, you get an opportunity that’s so cool, you sort of can’t believe that it’s happening. When I was told that I would have the chance to interview Dr. Colin Orion Chandler, a (then) grad student at Northern Arizona University, who is responsible for creating and leading the Active Asteroids project on Zooniverse, I was beyond thrilled. Every year, the Adler Planetarium in Chicago hires several interns to fill a variety of placements around the museum. As Zooniverse interns, Lola Fash, Tasnova, and I got to interview several researchers on three different projects: Transcribe Colored Conventions, NASA GLOBE Cloud Gaze, and my focus, Active Asteroids.
What are active asteroids, and why should we care?
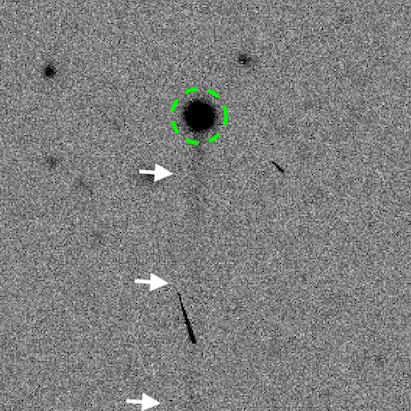
An active asteroid pictured on the Active Asteroids project About page, on the Zooniverse website. The green circle shows where a coma would appear, and the white arrows point to the tail of the asteroid. (Photo Credit: Zooniverse)
Active asteroids are bodies that follow a typical orbit for an asteroid, but, when observed, they are seen to have comae, which are clouds around the object, and tails, which form when water, dry ice, or dust streak out behind the object. These bizarre objects are extremely rare, so we don’t know much about them, but their tails and comae lead researchers to believe that they might have water on them. According to Dr. Chandler, “Water gives us fuel power. Things that we need to drink, to live, gives us things to breathe. It lets us grow food. I mean, it does a huge number of things. But you have to actually know where you might find it and how hard it is to get out of there.”
The hunt for active asteroids
Studying active asteroids could yield remarkable amounts of scientific information, but they are so faint that scientists have trouble finding them. However, the Dark Energy Camera in Chile is sensitive enough to photograph these asteroids, and it sometimes catches an asteroid in part of an image when it was photographing a different object altogether.
To get data from these archived images, Dr. Chandler and his team break the images into chips, cut out the asteroid, and then focus and enhance the image so that, if there is a tail, we will be able to see it. Will Burris, one of Dr. Chandler’s students, has helped streamline this process. All of these steps have been automated so that computers can process the nearly 30 million images that could contain active objects, and narrow it down to about 10 million where the objects are most likely to appear.
The image above demonstrates the process by which the Active Asteroids team finds images of potential active asteroids before they pass the images along to volunteers who can better identify them. (Photo Credit: Zooniverse)
The next step in the process is to identify whether or not there is a tail or coma around the object in the image, and that’s where volunteers come in. Computers are unable to identify active asteroids with a reasonable degree of accuracy, so the task falls to human minds. But, because of the sheer volume of images, Dr. Chandler and his team are unable to process them on their own. Instead, they harness the power of the crowd to classify these images for them, so they can process the data in a reasonable amount of time. When we spoke, Dr. Chandler explained why he opted to go this route, and why he chose to use Zooniverse specifically, stating that, without Zooniverse “It [Active Asteroids] wouldn’t have been as successful, not even by a fraction.”
Once Zooniverse volunteers have fully sorted the data, Dr. Chandler and his team examine the results and single out promising candidates that should be followed up on later with different telescopes. William Oldroyd, in particular, helps with this process. One improvement he’s looking to make is discarding feedback from overly optimistic citizens. Some citizens flag far more asteroids as active than what truly exists, which can throw off the data collected by the Active Asteroids team. The observation and analysis team hopes that they will be able to separate these overly optimistic classifications from the rest, so that they can improve the accuracy of the data that comes in.
With a complete dataset, Dr. Chandler as well as his project co-founder, Jay Kueny, and their chief science advisor, Chad Trujillo, examine the results. If an object was flagged as active, they follow up in one of two ways; direct observation and archival research.
Studying active asteroids
Pointing a telescope directly at a candidate active asteroid to look for more signs of activity seems like the most obvious way to confirm whether or not it is active. However, this is often difficult for several reasons.
For one, many candidates are so faint that it can be difficult for even the most advanced telescopes, such as the James Webb Space Telescope, to pick them up.
For another, they can only be observed at certain times in their orbits, and those intervals are usually years apart. Even if an asteroid is visible, it might not be active at that time, since there are many different reasons that an asteroid becomes active, and they each result in different patterns in activity. In an impact event, activity is temporary and only associated with the collision. Likewise, in the event of a rotational breakup, which occurs when an asteroid spins too quickly and falls apart as a result, an asteroid will only have activity corresponding with breakup events.
The image is one that volunteers classified on Active Asteroids. This object has already been confirmed as active. However, if one were to look at it with a telescope right now, it might not currently have a tail, or it might not be visible at all. (Image Credit: Zooniverse)
The asteroids that are most likely to show repeated activity are asteroids that are active due to sublimation, a process in which, as the asteroid gets closer to the Sun, the frozen carbon dioxide and water on its surface turn into gas and form a coma and tail behind it. Although this is a recurring event, a formerly active asteroid will not always be sublimating, so even if it can be observed, activity might not be detected.
For all of these reasons, when an object is identified as a promising candidate for activity, researchers prefer to follow up by looking through archived images that contain that object. When we talked, Dr. Chandler referred to “archival investigations” as “instant gratification” since he did not have to deal with the limitations of direct observation, and he could immediately confirm activity and further investigate the object by using images that were already taken.
Dr. Chandler and his team have already used the results from Active Asteroids to find and study several promising objects, and they are in the process of publishing their findings.
Reflections on my experience
All in all, working as a Zooniverse intern and learning about Active Asteroids has been an amazing experience. Going into the interview, I was worried that Dr. Chandler would be unapproachable and difficult to talk to. However, he seemed more than happy to discuss his work with me, and we actually talked well beyond the time when I’d originally expected the interview to stop. We were able to talk not just about Active Asteroids, but also what it’s like to be an LGBTQ+ person pursuing a career in science. As a young trans person, I often feel like I lack a connection with adults in my community, so getting to talk to someone with an identity similar to mine who was successfully pursuing a career in the field I aspire to join was an incredibly powerful experience. I wish I had a larger word count and some more time since I feel like I could probably write a whole book on interning at the Adler Planetarium and studying the Active Asteroids project on Zooniverse.
When I originally heard about active asteroids, I was mildly intrigued, but not all that excited about writing about them. Although I love all things space related, six months ago I would have said that asteroids are just about the most boring thing in space. However, after having done this project, I’ve become enthralled by active asteroids, and small planetary bodies in general. The idea of all the smaller rocks, tumbling through strange orbits in all kinds of places around the Sun, some with water or other invaluable resources that we may never even find, has found a special place in my heart. I hope this blog post has given you a piece of that.
By Lola Fash, Guest Writer and Adler Zooniverse Summer ’22 Teen Intern
This summer I had the opportunity to be a Zooniverse intern at the Adler Planetarium in Chicago, with two other interns, Tasnova and Dylan. As a group, we carried out a series of interviews with researchers leading Zooniverse projects. My focus project was the NASA GLOBE Cloud Gaze on Zooniverse. I led the interview with NASA scientist Marilé Colón Robles, the principal investigator for the project, and Tina Rogerson, the co-investigator and data analyst for the project.
Marilé Colón Robles (right) and Tina Rogerson (left) outdoors working on GLOBE Clouds. Photo Credit: Tina Rogerson.
NASA GLOBE Cloud Gaze is a collaboration between the Global Learning and Observations to Benefit the Environment (GLOBE) Program, NASA’s largest citizen science program, and Zooniverse. When NASA began to study clouds to understand how they affect our climate, they launched about 20 satellites to collect data on Earth’s clouds. Unfortunately, these satellites are limited to only collecting data from above the clouds, which only paints half of the picture for scientists. They needed data from the ground to complete the picture. In 2018, they launched the first ever cloud challenge on GLOBE Clouds, which asked people all over the world to submit observations of clouds and photographs of their sky through the GLOBE Observer app. People responded faster than expected, submitting over 50,000 observations across 99 different countries during the month-long challenge. Because of the high volume, it would take months for researchers alone to go through each submission. So instead, they sought help, thus birthing the Zooniverse CLOUD GAZE project, where people help them classify these photos. Zooniverse participants classify the photos by cloud cover (what percent of the sky is covered by clouds), what type of cloud is in the image, and if they see any other conditions like haze, fog, or dust.
Why are clouds so important?
We see the immediate effects of these clouds in our atmosphere. For example, when you go out on a sunny day and the sun gets blocked by low altitude clouds, you feel cooler right away. But rather than looking at short-term effects, the CLOUD GAZE project is working to understand the long-term role clouds play on our climate.
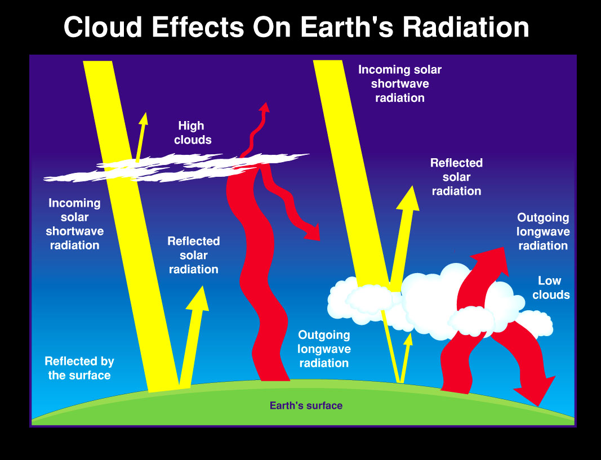
Clouds play a significant role in maintaining Earth’s climate. They control Earth’s energy budget, the balance between the energy the Earth receives from the Sun and the energy the Earth loses back into outer space, which determines Earth’s temperature. The effects clouds have varies by type, size, and altitude.
Credit: NASA GLOBE CLOUD GAZE
Cirrus, cirrostratus, and cirrocumulus clouds are high altitude clouds that allow incoming radiation to be absorbed by Earth, then trap it there, acting like an insulator and increasing Earth’s temperature. Low altitude clouds, such as stratus and cumulonimbus, keep our planet from absorbing incoming radiation, and allow it to radiate energy back into space.
The classifications made by Zooniverse participants are needed to determine the amount of solar radiation that is reflected or absorbed by clouds before reaching the surface of Earth and how that correlates to climate over time.
In my interview, I had the honor to meet with NASA Scientists Marilé Colón Robles and Tina Rogerson, learn more about the NASA GLOBE Cloud Gaze effort, and hear their predictions for the future.
Clip 1: Introductions
This first clip is of Marilé, Tina, and me introducing ourselves to one another. Note: The other participants you’ll see in the recordings are Sean Miller (Zooniverse designer and awesome mentor for us interns) and Dylan and Tasnova (my fellow interns).
Clip 2: What prompted you to start NASA GLOBE Cloud Gaze on Zooniverse?
Quote from Tina from this Clip 2: “We have 1.8 million photographs of the sky. We want to know what’s in those photographs.”
Clip 3: What have your GLOBE participants been telling you about what they’re seeing in their local environments about the impacts of climate change?
What are your hopes and goals for this project?
In the interview, I asked them about their hopes and broader goals for the project. They talked about how in order to really understand climate change, we need to gather the best data possible. The majority of the data we have on clouds are from the 20th century. One of the project goals was to update our databases on clouds in order to conduct proper research on climate change. Tina Rogerson, Cloud Gaze’s data analyst, gathers this information and compiles it into easily accessible files. The files include data from a range of different sources: satellites, Globe observations, and Zooniverse classifications (see https://observer.globe.gov/get-data). They give people a chance to analyze clouds at different points and connect the dots to analyze the whole.
Scientist Marilé Colón Robles explained that one of the goals of the project is to make a climatology of cloud types based on the data they have collected. This would help us have a record on how the clouds have changed in a given location in relation to the climate of that area. We would have information on the entire world, every single continent, yes, including Antarctica.
Why did I pick this project to focus on?
I chose this project because I wanted to challenge myself. I have always shied away from topics and conversations about climate change and global warming. I felt I could never fully comprehend it so I should instead avoid it by all means possible. My fellow interns and I had three projects to choose from: Transcribe Color Convention, Active Asteroids, and NASA GLOBE CLOUD GAZE. If it were any other day, I would have chosen one of the first two projects to be my focus but I wanted to change, to try something new. The only way to grow is to step out of your comfort zone and I am so glad I did.
People make the mistake of believing that climate change can’t be helped and that after our Earth becomes inhabitable we can just pull a Lost In Space and find a different planet to live on. I had the chance to speak with Dr. Michelle B. Larson, CEO of Adler Planetarium, and we talked about how there isn’t another planet for us to go to if we mess this one up. Even if there was, it would take years and a lot of resources to ready the planet for ourselves. Those are resources and years that we could be spending on fixing our home.
The CLOUD GAZE focused on one of the most important and understudied factors in Earth’s climate – clouds. People all over the world are helping in their own way to help save the planet. Some make sure to always recycle their garbage. Some take public transportation more often, and switch to electronic vehicles to cut down on their carbon footprint. You and I can help by taking pictures of our sky, submitting it in the GLOBE Observer app, and by going to the Zooniverse Cloud GAZE project, classifying as little as 10 images of clouds per day to multiply the data on clouds, which in turn helps further our research and our understanding of climate change.
The world's largest and most popular platform for people-powered research. This research is made possible by volunteers—millions of people around the world who come together to assist professional researchers.