Engaging Faith-based Communities in Citizen Science through Zooniverse was an initiative designed to broaden participation in people-powered research (also referred to as citizen science) among religious and interfaith communities by helping them to engage with science through Zooniverse. Citizen science is a powerful way to build positive, long-term relationships across diverse communities by “putting a human face” on science and scientists. Participating in real scientific research is a great way to learn about the process of science as well as the scientists who conduct research.
The Engaging initiative provided models for how creative partnerships can be formed between scientific and religious communities that empower more people to become collaborators in the quest for knowledge. It included integrating Zooniverse projects into seminary classes as well as adult, youth, and intergenerational programs of religious communities; and promoting Zooniverse among interfaith communities concerned with environmental justice. Among other things, the project’s evaluation highlighted the need for scientists to do a better job of engaging with religious audiences in order to address racial and gender disparities in science. I encourage Zooniverse research teams to check out the series of short videos recently released by the AAAS Dialogue on Science, Ethics, and Religion to help scientists engage more effectively with communities of faith. By interacting personally with these communities and helping to “put a human face” on science, you may not only increase participation in your research projects, but help in the effort to diversify science in general.
Despite the difficulties imposed by the pandemic, I’m encouraged by what the Engaging initiative achieved, and the possibilities for expanding its impact in the future! The summary article of this project was published on March 28, 2022 by the AAAS Dialogue on Science, Ethics, and Religion.
The project team thanks the Alfred P. Sloan Foundation for supporting this project. Any opinions, findings, or recommendations expressed are those of the project team and do not necessarily reflect the views of the Sloan Foundation.
Over the years a growing number of companies have included Zooniverse in their digital engagement and volunteer efforts, connecting their employee network with real research projects that need their help.
It’s been lovely hearing the feedback from employees:
“This was an awesome networking event where we met different team members and also participated in a wonderful volunteer experience. I had so much fun!”
“This activity is perfectly fitted to provide remote/virtual support. You can easily review photos from anywhere. Let’s do this again!”
“Spotting the animals was fun; a nice stress reliever!’
The impact of these partnerships on employees and on Zooniverse has been tremendous. For example, in 2020 alone, 10,000+ Verizon employees contributed over a million classifications across dozens of Zooniverse projects. With companies small to large incorporating Zooniverse into their volunteer efforts, this new stream of classifications has been a tremendous boon for helping propel Zooniverse projects towards completion and into the analysis and dissemination phases of their efforts. And the feedback from employees has been wonderful — participants across the board express their appreciation for having a meaningful way to engage in real research through their company’s volunteer efforts.
A few general practices that have helped set corporate volunteering experiences up for success:
Focus and choice: Provide a relatively short list of recommended Zooniverse projects that align with your company’s goals/objectives (e.g., topic-specific, location-specific, etc.), but also leave room for choice. We have found that staff appreciate when a company provides 3-6 specific project suggestions (so they can dive quickly into a project), as well as having the option to choose from the full list of 70+ projects at zooniverse.org/projects.
Recommend at least 3 projects: This is essential in case there happens to be a media boost for a given project before your event and the project runs out of active data*. Always good to have multiple projects to choose from.
Team building: Participation in Zooniverse can be a tremendous team building activity. While it can work well to just have people participate individually, at their own convenience, it also can be quite powerful to participate as a group. We have created a few different models for 1-hour, 3-hour, and 6-hour team building experiences. The general idea is that you start the session as a group to learn about Zooniverse and the specific project you’ll be participating in. You then set a Classification Challenge for the hour (e.g., as a group of 10, we think we can contribute 500 classifications by the end of the hour). You play music in the background while you classify and touch base halfway through to see how you’re doing towards your goal (by checking your personal stats at zooniverse.org) and to share interesting, funny, and/or unusual images you’ve classified. At the end of the session, you celebrate reaching your group’s Classification Challenge goal and talk through a few reflection questions about the experience and other citizen science opportunities you might explore in the future.
Gathering stats: Impact reports have been key in helping a company tell the story of the impact of their corporate volunteering efforts, both internally to their employee network and externally to their board and other stakeholders.
Some smaller companies (or subgroups within a larger company) manually gather stats about their group’s participation in Zooniverse. They do this by taking advantage of the personal stats displayed within the Zooniverse.org page (e.g., number of classifications you’ve contributed). They request that their staff register and login to Zooniverse before participating and send a screenshot of their Zooniverse.org page at the end of each session. The team lead then adds up all the classifications and records the hours spent as a group participating in Zooniverse.
If manual stats collection is not feasible for your company, don’t hesitate to reach out to us at contact@zooniverse.org to explore possibilities together.
We’ve also created a variety of bespoke experiences for companies who are interested in directly supporting the Zooniverse. Please email contact@zooniverse.org if you’re interested in exploring further and/or have any questions.
*Zooniverse project datasets range in size; everything from a project’s dataset being fully completed within a couple weeks (e.g., The Andromeda Project) to projects like Galaxy Zoo and Snapshot Serengeti that have run and will continue to run for many years. But even for projects that have data that will last many months or years, standard practice is to upload data in batches, lasting ~2-4 months. When a given dataset is completed, this provides an opportunity for the researchers to share updates about the project, interim results, etc. and encourage participation in the next cycle of active data.
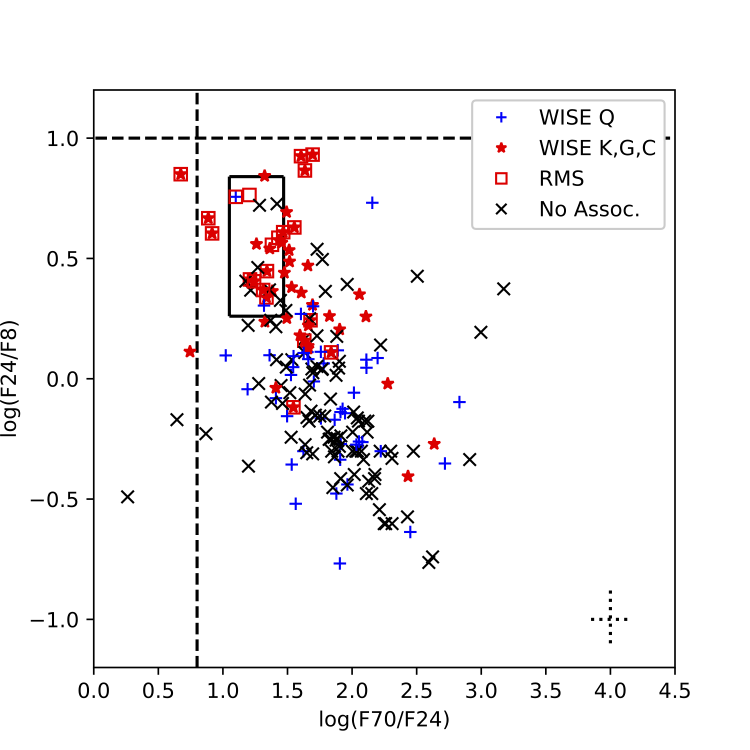
What are “Yellowballs?” Shortly after the Milky Way Project (MWP) was launched in December 2010, volunteers began using the discussion board to inquire about small, roundish “yellow” features they identified in infrared images acquired by the Spitzer Space Telescope. These images use a blue-green-red color scheme to represent light at three infrared wavelengths that are invisible to our eyes. The (unanticipated) distinctive appearance of these objects comes from their similar brightness and extent at two of these wavelengths: 8 microns, displayed in green, and 24 microns, displayed in red. The yellow color is produced where green and red overlap in these digital images. Our early research to answer the volunteers’ question, “What are these `yellow balls’?” suggested that they are produced by young stars as they heat the surrounding gas and dust from which they were born. The figure below shows the appearance of a typical yellowball (or YB) in a MWP image. In 2016, the MWP was relaunched with a new interface that included a tool that let users identify and measure the sizes of YBs. Since YBs were first discovered, over 20,000 volunteers contributed to their identification, and by 2017, volunteers catalogued more than 6,000 YBs across roughly 300 square degrees of the Milky Way.
New star-forming regions. We’ve conducted a pilot study of 516 of these YBs that lie in a 20-square-degree region of the Milky Way, which we chose for its overlap with other large surveys and catalogs. Our pilot study has shown that the majority of YBs are associated with protoclusters – clusters of very young stars that are about a light-year in extent (less than the average distance between mature stars.) Stars in protoclusters are still in the process of growing by gravitationally accumulating gas from their birth environments. YBs that represent new detections of star-forming regions in a 6-square-degree subset of our pilot region are circled in the two-color (8 microns: green, 24 microns: red) image shown below. YBs present a “snapshot” of developing protoclusters across a wide range of stellar masses and brightness. Our pilot study results indicate a majority of YBs are associated with protoclusters that will form stars less than ten times the mass of the Sun.
YBs show unique “color” trends. The ratio of an object’s brightness at different wavelengths (or what astronomers call an object’s “color”) can tell us a lot about the object’s physical properties. We developed a semi-automated tool that enabled us to conduct photometry (measure the brightness) of YBs at different wavelengths. One interesting feature of the new YBs is that their infrared colors tend to be different from the infrared colors of YBs that have counterparts in catalogs of massive star formation (including stars more than ten times as massive as the Sun). If this preliminary result holds up for the full YB catalog, it could give us direct insight into differences between environments that do and don’t produce massive stars. We would like to understand these differences because massive stars eventually explode as supernovae that seed their environments with heavy elements. There’s a lot of evidence that our Solar System formed in the company of massive stars.
The figure below shows a “color-color plot” taken from our forthcoming publication. This figure plots the ratios of total brightness at different wavelengths (24 to 8 microns vs. 70 to 24 microns) using a logarithmic scale. Astronomers use these color-color plots to explore how stars’ colors separate based on their physical properties. This color-color plot shows that some of our YBs are associated with massive stars; these YBs are indicated in red. However, a large population of our YBs, indicated in black, are not associated with any previously studied object. These objects are generally in the lower right part of our color-color plot, indicating that they are less massive and cooler then the objects in the upper left. This implies there is a large number of previously unstudied star-forming regions that have been discovered by MWP volunteers. Expanding our pilot region to the full catalog of more than 6,000 YBs will allow us to better determine the physical properties of these new star-forming regions.
Volunteers did a great job measuring YB sizes! MWP volunteers used a circular tool to measure the sizes of YBs. To assess how closely user measurements reflect the actual extent of the infrared emission from the YBs, we compared the user measurements to a 2D model that enabled us to quantify the sizes of YBs. The figure below compares the sizes measured by users to the results of the model for YBs that best fit the model. It indicates a very good correlation between these two measurements. The vertical green lines show the deviations in individual measurements from the average. This illustrates the “power of the crowd” – on average, volunteers did a great job measuring YB sizes!
Stay tuned… Our next step is to extend our analysis to the entire YB catalog, which contains more than 6,000 YBs spanning the Milky Way. To do this, we are in the process of adapting our photometry tool to make it more user-friendly and allow astronomy students and possibly even citizen scientists to help us rapidly complete photometry on the entire dataset.
Our pilot study was recently accepted for publication in the Astrophysical Journal. Our early results on YBs were also presented in the Astrophysical Journal, and in an article in Frontiers for Young Minds, a journal for children and teens.
For the second year in a row, we’re honoring the hundreds of thousands of contributors, research teams, educators, Talk moderators, and more who make Zooniverse possible. This second edition of Into the Zooniverse highlights another 40 of the many projects that were active on the website and app in the 2019 – 20 academic year.
In that year, the Zooniverse has launched 65 projects, volunteers have submitted more than 85 million classifications, research teams have published 35 papers, and hundreds of thousands of people from around the world have taken part in real research. Wow!
To get your copy of Into the Zooniverse: Vol II, download a free pdf here or order a hard copy on Blurb.com. Note that the cost of the book covers production and shipping; Zooniverse does not receive profit through sales. According to the printer, printing and binding take 4-5 business days, then your order ships. To ensure that you receive your book before December holidays, you can use this tool to calculate shipping times.
Now it’s even easier to contribute to science from your phone!
On any crowded public bus (before the pandemic), people sat next to each other, eyes fixed on their phones, smiling, swiping.
What were they all doing? Using a dating app, maybe. Or maybe they were separating wildcam footage of empty desert from beautiful birds. Maybe they were spotting spiral arms on faraway galaxies.
Maybe one of them was you!
We’ve loved seeing the participation in the Zooniverse through the mobile app (available for iOS and Android) over the past two years. So we made it even easier for you to do that wherever you swipe these days—a park bench, or maybe your home. (Please don’t swipe and drive).
Right now, you can go into the app and contribute to Galaxy Zoo Mobile, Catalina Outer Solar System Survey, Disk Detective, Mapping Historic Skies, Nest Quest Go, or Planet Four: Ridges. And we have more projects on the way!
What’s new in the app
When you update to version 2.8.2, you’ll notice a slick new look. At the very top, there’s now an “All Projects” category. This will show you everything available for mobile—with the projects that need your help the most sorted at the very top! You can also still choose a specific discipline, of course.
That’s it for features that are totally new, but a lot of features in this version are fixed. No more crashing when you tap on browser projects. A lot fewer project-related crashes. Animated gifs, which previously worked only on iOS, now also work on Android—so researchers can show you an image that changes over time.
What’s more—and you’ll never see this, but it’s important to us, the developers—we’ve made a lot of changes that help us keep improving the app. We have better crash reporting mechanisms and more complete automated testing. We also updated all of our documentation so that developers from outside our team can contribute to the app, too! We’d love to be a go-to open source project for people who are learning, or working in, React Native (the platform on which our app is built).
Aggregate Functionality
The full list of functionalities now includes:
Swipe (binary question [A or B.] response)
Single-answer question (A, B, or C)
Multi-answer question (any combination of A, B, and C.)
Rectangle drawing task (drawing a rectangle around a feature within a subject)
Single-image subjects
Multi-image subjects (e.g. uploading 2+ images as a single subject; users swipe up/down to display the different images)
Animated gifs as subjects
Subject auto-linking (automatically linking subjects retired from one workflow into another workflow of interest on the same project)
Push notifications (sending messages/alerts about new data, new workflows, etc., via the app)
Preview (an owner or collaborator on a project in development being able to preview a workflow in the ‘Preview’ section of the mobile app)
Beta Review (mobile enabled workflows are accessible through the ‘Beta Review’ section of the app for a project in the Beta Review process; includes an in-app feedback form)
Ability to see a list of all available projects, as well as filter by discipline (with active mobile app workflows listed at the top)
We also carried out a number of infrastructure improvements, including:
Upgrades to the React Native libraries we use
Created a staging environment to test changes before they are implemented in full production
Additional test coverage
Implemented bug reporting and tracking
Complete documentation, so open source contributors can get the app running from our public code repository
And a myriad of additional improvements like missing icons no longer crashing the app, improvements to the rectangle drawing task, etc.
Note: we will continue developing the app; this is just the end of this phase of effort and a great time to share the results.
If you’re leading a Zooniverse project and have any questions about where in the Project Editor ‘workflow’ interface to ‘enable on mobile’, don’t hesitate to email contact@zooniverse.org. And/or if you’re a volunteer and wonder if workflow(s) on a given project could be enabled on mobile, please post in that project’s Talk to start the conversation with the research team and us. The more, the merrier!
Looking forward to having more projects on the mobile app!
A Few Stats of Interest:
Since Jan 1, 2020:
6.2 million classifications submitted via the app (that’s 7% of 86.7 million classifications total through Zooniverse projects)
18,000 installations on iOS + 17,000 on Android
Current Active Users (people who have used the app in the last 30 days):
1,800 on iOS + 7,700 on Android
Previous Blog Posts about the Zooniverse Mobile App:
The following is an update from the SuperWASP Vairable Stars research team. Enjoy!
Welcome to the Spring 2020 update! In this blog, we will be sharing some updates and discoveries from the SuperWASP Variable Stars project.
What are we aiming to do?
We are trying to discover the weirdest variable stars!
Stars are the building blocks of the Universe, and finding out more about them is a cornerstone of astrophysics. Variable stars (stars which change in brightness) are incredibly important to learning more about the Universe, because their periodic changes allow us to probe the underlying physics of the stars themselves.
We have asked citizen scientists to classify variable stars based on their photometric light curves (the amount of light over time), which helps us to determine what type of variable star we’re observing. Classifying these stars serves two purposes: firstly to create large catalogues of stars of a similar type which allows us to determine characteristics of the population; and secondly, to identify rare objects displaying unusual behaviour, which can offer unique insights into stellar structure and evolution.
We have 1.6 million variable stars detected by the SuperWASP telescope to classify, and we need your help! By getting involved, we can build up a better idea of what types of stars are in the night sky.
What have we discovered so far?
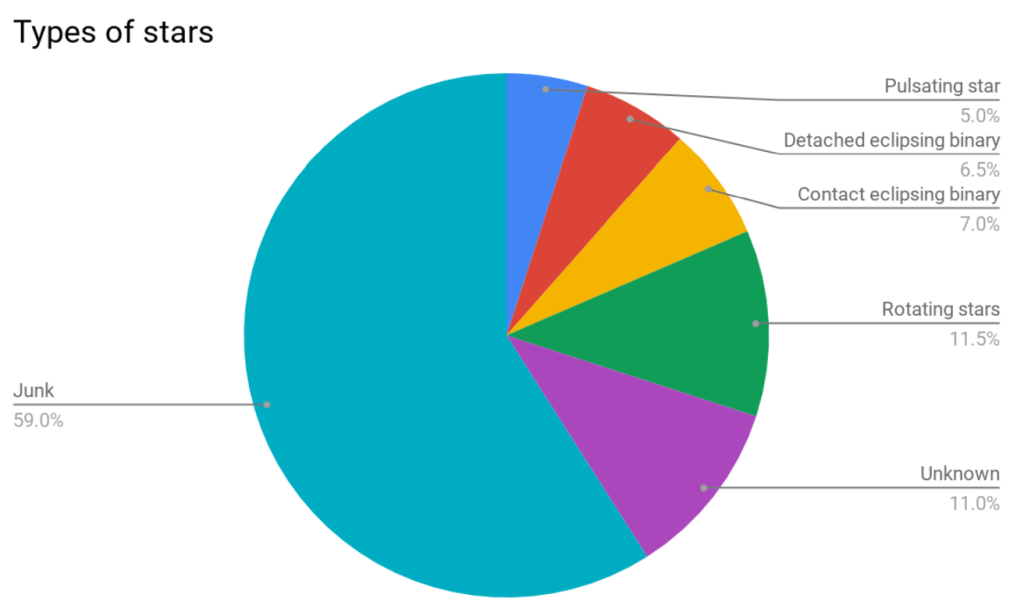
We’ve done some initial analysis on the first 300,000 classifications to get a breakdown of how many of each type of star is in our dataset.
So far it looks like there’s a lot of junk light curves in the dataset, which we expected. The programme written to detect periods in variable stars often picks up exactly a day or a lunar month, which it mistakes for a real period. Importantly though, you’ve classified a huge number of real and exciting light curves!
We’re especially excited to do some digging into what the “unknown” light curves are… are there new discoveries hidden in there? Once we’ve completed the next batch of classifications, we’ll do some more to see whether the breakdown of types of stars changes.
An exciting discovery…
In late 2018, while building this Zooniverse project, we came across an unusual star. This Northern hemisphere object, TYC-3251-903-1, is a relatively bright object (V=11.3) which has previously not been identified as a binary system. Although the light curve is characteristic of an eclipsing contact binary star, the period is ~42 days, notably longer than the characteristic contact binary period of less than 1 day.
Spurred on by this discovery, we identified a further 16 candidate near-contact red giant eclipsing binaries through searches of archival data. We were excited to find that citizen scientists had also discovered 10 more candidates through this project!
Figure 1: Artist’s impression of a contact binary star [Mark A. Garlick] Over the past 18 months, we’ve carried out an observing campaign of these 27 candidate binaries using telescopes from across the world. We have taken multi-colour photometry using The Open University’s own PIRATE telescope, and the Las Cumbres Observatory robotic telescopes, and spectroscopy of Northern candidates with the Liverpool Telescope, and Southern candidates using SALT. We’ve also spent two weeks in South Africa on the 74-inch telescope to take further spectroscopy.
Of the 10 candidate binaries discovered by citizen scientists, we were happy to be able to take spectroscopic observations for 8 whilst in South Africa, and we have confirmed that at least 2 are, in fact, binaries! Thank you citizen scientists!
Why is this discovery important?
Figure 2: V838 Mon and its light echo [ESA/NASA]
The majority of contact or near-contact binaries consist of small (K/M dwarf) stars in close orbits with periods of less than 1 day. But for stars in a binary in a contact binary to have such long periods requires both the stars to be giant. This is a previously unknown configuration…
Interestingly, a newly identified type of stellar explosion, known as a red nova, is thought to be caused by the merger of a giant binary system, just like the ones we’ve discovered.
Red novae are characterised by a red colour, a slow expansion rate, and a lower luminosity than supernovae. Very little is known about red novae, and only one has been observed pre-nova, V1309 Sco, and that was only discovered through archival data. A famous example of a possible red nova is the 2002 outburst in V838 Mon. Astronomers believe that this was likely to have been a red nova caused by a binary star merger, forming the largest known star for a short period of time after the explosion.
So, by studying these near-contact red giant eclipsing binaries, we have an unrivalled opportunity to identify and understand binary star mergers before the merger event itself, and advance our understanding of red novae.
What changes have we made?
Since the SuperWASP Variable Stars Zooniverse project started, we’ve made a few changes to make the project more enjoyable. We’ve reduced the number of classifications needed to retire a target, and we’ve also reduced the number of classifications of “junk” light curves needed to retire it. This means you should see more interesting, real, light curves.
We’ve also started a Twitter account, where we’ll be sharing updates about the project, the weird and wacky light curves you find, and getting involved in citizen science and astronomy communities. You can follow us here: www.twitter.com/SuperWASP_stars
What’s next?
We still have thousands of stars to classify, so we need your help!
Once we have more classifications, we will be beginning to turn the results into a publicly available, searchable website, a bit like the ASAS-SN Catalogue of Variable Stars (https://asas-sn.osu.edu/variables). Work on this is likely to begin towards the end of 2020, but we’ll keep you updated.
We’re also working on a paper on the near-contact red giant binary stars, which will include some of the discoveries by citizen scientists. Expect that towards the end of 2020, too.
Otherwise, watch this space for more discoveries and updates!
We would like to thank the thousands of citizen scientists who have put time into this Zooniverse project. If you ever have any questions or suggestions, please get in touch.
We have updated our process! For the latest information, new functionality, and exciting new opportunities, please visit our most recent blog post on service learning support.
We’ve been so thankful and appreciative of how many students and organizations participate in Zooniverse to fulfill volunteering/service hour requirements for graduation, scholarships, etc.
If you’re considering doing the same, we recommend that organizations place at the forefront what students/participants get out of these experiences beyond contributing time and classifications. Rather than creating busy work, we favor a model where participants take time to reflect on how their efforts (and the community’s collective efforts) are contributing to our understanding of our world and the broader universe.
Here is one approach for constructing a productive and rewarding volunteer experience for your organization:
Step 1: Share this opportunity with your Organization
Email your organization to see if participation in Zooniverse can be used to fulfill volunteering or other participation requirements. Share this blog post with them so they understand what you would be doing and how you’ll ‘document’ your participation (see Step 8 below).
Step 2: Register at Zooniverse.org
Create a Zooniverse account by clicking ‘Register’ in the upper-right of the Zooniverse.org homepage (only a name and email are required).
Registering is not required to participate in Zooniverse. But it is useful in this case in order to provide a record of participation.
Step 3: Zooniverse background info
Watch this brief animation and video for background/context about the Zooniverse, the world’s largest platform for people-powered research, with 100 active projects and 2 million people around the world participating. Every Zooniverse project is led by a different research team, spanning a wide range of subjects that include: identifying planets around distant stars (PlanetHunters.org), studying the impact of climate change on animals (SnapshotSafari.org) and plants (FloatingForests.org), tracking resistance to antibiotics (Bash the Bug), transcribing handwritten documents (antislaverymanuscripts.org), and more. The collective efforts of Zooniverse projects have resulted in over 200 research publications to date.
Step 4: Choose your project(s)
Choose from the full list of ~100 active Zooniverse projects (see zooniverse.org/projects) or choose from the curated lists of projects below that tend to work well with different age groups, as selected by the Zooniverse team:
Sometimes projects temporarily run out of data sets before a volunteer has completed the hours-requirements they are working toward, so having more than one project in mind is a good idea.
Step 5: Learn a bit about the project before diving in
Consider these Reflection Questions, or other similar questions. The questions explore the ‘why’ behind this experience. Why do the researchers need your help? How might the results help science? Are you interested in participating in other projects of this type, and why or why not?
For Organizations: Consider sending these via a Google Form or other survey tool for participants to submit responses to these questions. Note: before using the example form above, make a copy of the Google form and send the survey from your own account to make sure you can access the responses.
Extension opportunities:
Each project has a ‘Talk’ discussion forum associated with it (e.g., https://www.zooniverse.org/projects/mrniaboc/bash-the-bug/talk). This is where the researchers and participants from around the world chat with each other — asking questions about the science, weird things people see while classifying, new discoveries, & more. First, explore the discussion threads and check out some of the questions other people have asked. If you’re feeling comfortable, ask the researchers a question about the science, being a scientist, etc. You might start with a question you asked as part of the ‘Reflection Questions’ activity above. The researchers are keen to hear your questions and engage with you. Check back later to see the response, or watch for Talk email notifications, if you’ve enabled them.
Post-experience (a lifetime of engagement): Check out other Zooniverse projects and check out NASA’s Citizen Science project list and SciStarter for other citizen science opportunities. And please do share about citizen science with family and friends (peer networks make a BIG difference in what people try).
Step 8: Document your participation to fulfill your requirements
Once signed in at Zooniverse.org, you’ll see your display name and your total classification count. (If you hover over the doughnut-ribbon in the center top of the page, you’ll see the classification counts for each specific project you’ve participated in.)
Please note that there is no built-in time-tracker within Zooniverse. Many organizations encourage participants to use the number of classifications they’ve contributed as a proxy for time spent on the site. On average, a person contributes 20-75 classifications/hour on most projects (this ranges widely depending on the difficulty of the tasks, the number of tasks for a given classification, etc.).
For example, if someone has done 100 classifications, you can estimate that they’ve spent ~2 hours classifying on Zooniverse; e.g., 2 hours x 50 classifications / hour = 100 classifications. The Organization should add ~45 minutes to this time estimate for the time it takes to carry out the additional ‘meta’ elements of the experience outlined above.
Please note – because we are a small organization and 1000s of students each week are participating in Zooniverse as volunteers, we (the internal Zooniverse team) are not able to sign individual’s ‘certificates of completion’ or other records of that type for volunteer hours. Instead, organizations encourage their participants to take a screenshot of their signed-in Zooniverse.org page showing their personal stats. This screenshot serves as a proxy for documentation of your effort.
Another option is to participate in the following specific Zooniverse projects. The research teams leading those efforts have the capacity to provide certificates.
Note: Best practice is to allow at least two weeks between requesting the required information and any deadlines you may have. It may take longer if the research team is in the field or dealing with other tasks.
For Organizations: Consider using a Google Form or other survey instrument for participants to submit their classification count and a screenshot of their Zooniverse.org page. Note: make a copy of the Google form and send it from your account so you can access the responses.
Other Information
If you need to reference a 501(c)(3):
While Chicago’s Adler Planetarium, one of the hosts of the Zooniverse web development team, is a 501(c)(3), the Zooniverse is not. Organizations that need to link explicitly to a 501(c)(3) for their volunteering efforts use the Adler Planetarium as the reference. Documentation of the Adler Planetarium’s 501(c)(3) status is provided here.
Future Work:
We recognize it would be helpful to have an easier way to share participation information with organizations for these purposes (though this will need to be done in a very thoughtful way). Please note that because we are a grant-funded web development team, enhancements of this type take time to design, build and implement. If you or your organization have suggestions for how best to share this information, or are interested in helping to support this effort via collaborative grant-writing or otherwise, please let us know.
THANK YOU!
As always, please don’t hesitate to reach out to contact@zooniverse.org if you have any questions or suggestions.
As schools, workplaces, public spaces, and institutions across the globe close in response to COVID-19, we are aware that, for many people, online platforms like Zooniverse can function as a way to continue to have an impact and remain engaged with the world.
We cannot thank you enough for participating in Zooniverse and creating a welcoming and supportive space for all.
Below is a list of resources educators have used in classrooms that also work well remotely/online. Key to keep in mind is that Zooniverse projects are a great way to expose learners to new opportunities and ways of engaging in real research. These resources are meant to spark curiosity, learning, and exposure to research and the broader world. We encourage you to especially consider what students can gain from the process of participating. Remember: this is an opportunity for experiential learning, not a platform for creating busy work.
Note – there is no age limit for participating in Zooniverse projects, but children under the age of 16 need parent or guardian approval before creating their own Zooniverse account (see here for more details).
Designed for 11-13 year olds, but the content can easily scale down for younger audiences.
Great way to engage if you love looking at photos of wild animals and want to investigate ecological questions. The interactive map allows you to explore trail camera data and filter and download data to carry out analyses and test hypotheses.
Educators can set up private classrooms, invite students to join, curate data sets, and get access to the guided activities and supporting educational resources.
Individual explorers also welcome – you don’t need to be part of a classroom to participate.
An example set of lessons based around Wildcam Labs, focused on using wildlife camera citizen science projects to engage students in academic language acquisition
A Zooniverse – NASA collaboration through which students learn about citizen science, explore how astronomers search for planets around distant stars, participate directly in the search for exoplanets through PlanetHunters.org, and then design and draw their own planetary system.
Developed by Chicago’s Adler Planetarium Education Specialist Julie Feldt and Adler Director of Teen Programs Kelly Borden.
Through this lesson students observe, record, and document specimens, become a part of the Zooniverse Notes from Nature project, transcribe specimens, connect art and science, and sketch birds in a science notebook.
Designed for middle school classrooms, but the content can easily scale up for older audiences.
See description above.
Astro101 with Galaxy Zoo
Designed for undergraduate non-major introductory astronomy courses, but the content has been used in many high-school classrooms as well.
Students learn about stars and galaxies through 4 half-hour guided activities and a 15-20 hour research project experience in which they analyze real data (including a curated Galaxy Zoo dataset), test hypotheses, make plots, and summarize their findings.
Developed by Julie Feldt, Thomas Nelson, Cody Dirks, Dave Meyer, Molly Simon, and colleagues.
For both Wildcam and Astro101 Activities
Educators can set up private classrooms, invite students to join, curate data sets, and get access to the guided activities and supporting educational resources.
Individual explorers also welcome – you don’t need to be part of a classroom to participate.
Through the Zooniverse FloatingForests.org project, researchers are striving to understand the impact of climate change on giant kelp forests, an indicator of the health of our oceans. In this lab, students analyze Floating Forest and other ocean data to explore their own research questions.
Developed by Cal State – Monterey Bay faculty Dr. Alison Haupt and colleagues
We’d love to hear about your experiences with Zooniverse. Join the conversation in our ‘Talk’ discussion forum around Education and the Zooniverse. There’s a wonderful community there of formal and informal educators and students who are interested in sharing resources and ideas.
If you need a record of your students’ contributions:
You can keep track of how many classifications you’ve contributed if you register (providing a username and email address) within Zooniverse.org. Once signed in, at Zooniverse.org you’ll see your display name and your total classification count. If you hover over the circle surrounding your avatar, you’ll see the classification counts for each specific project you’ve participated in. Some teachers have their students share a screenshot of this zooniverse.org page as a record of contributions.
Please note that there is no built-in time-tracker within Zooniverse. However, participants can use the number of classifications they’ve contributed as a proxy for time spent on the site. On average, a person contributes 20-75 classifications/hour on most projects. So, for example, if a student has done 100 classifications, you can estimate that they’ve spent ~2 hours classifying on Zooniverse; e.g., 2 hours x 50 classifications / hour = 100 classifications.
The Chicago Zooniverse team had a great time celebrating Earth Day with members of the community at the Adler Planetarium and Chicago Botanic Garden.
At the Adler Planetarium’s EarthFest celebration on Saturday, April 13, guests were able to participate in an in-real-life version of Floating Forests, tracing areas of kelp from a satellite image onto tracing paper to see how a consensus result might be reached in the online version. Online at https://www.zooniverse.org/projects/zooniverse/floating-forests, you’ll be able to do this same activity, helping researchers learn how Giant Kelp forests change over time.
Tracing Giant Kelp forests at the Adler’s Earth Fest celebration
Learning about Zooniverse during Adler’s Earth Fest celebration
The next day at the Chicago Botanic Garden’s UnEarth Science Festival, visitors learned about the parts of a plant though a matching activity that segued into Rainforest Flowers, a Zooniverse project helping researchers at the Field Museum in Chicago to create a database of images of plants from the tropical forests of Central and South America.
Sharing Zooniverse at Chicago Botanic Garden’s UnEarth Science Festival
Learning about parts of a plant
Talking to visitors about volunteer opportunities
Sharing the Zooniverse app, suitable for all ages
We love meeting the community! If you missed us this time, keep your eye on this blog for our next event.
This coming Saturday 13th April is Citizen Science Day, an ‘annual event to celebrate and promote all things citizen science’. Here at the Zooniverse, one of our team members will be posting each day this week to share with you their favourite Zooniverse projects. Today’s post is from Grant Miller, project manager of the Zooniverse team at the University of Oxford.
Having been at the Zooniverse for almost six years and helped over one hundred research teams launch their project on the Zooniverse platform I find it very difficult to choose just one of them as my favourtie. However, unlike Helen did on Tuesday, I’m going to give it a try 😛
For me it’s got to be the very first project that was pitched to me on my first day of the job back in 2013 – Penguin Watch! Over the last decade the lead researcher Tom Hart and his team have been travelling to the Southern Ocean and Antarctica to place time-lapse cameras looking at penguin nests. They now collect so many images each year the cannot do their science without the help of the Zooniverse crowd. This projecy perfectly demonstrates the key elements which go into making a truly great citizen science project:
It has a clear and relatable research goal: Help count penguins so we can understand how over-fishing and climate change is affecting their populations, and then use that information to influence policy makers.
It has an extremely simple task that for now can only be done accurate by human eyes: Click on the penguins in the image. It’s so simple we have 4-year-old children helping their parents do it!
It has an amazing and engaged research team and volunteer community: Even though they are a very small team the scientists take plenty of time to communicate with their volunteer community via the Talk area of the project, newsletters, and social media channels. There is also a fantastic core group of volunteer moderators who put in so much effort to make sure the project is running as well as it should.
Half a million king penguins at St Andrews Bay, South Georgia.
In addition to all of this I was lucky enough to join them on one of their Antarctic expeditions last year, as they went down to maintain their time-lapse cameras and collect the data that goes into Penguin Watch. You can see my video diary (which I’m posting once per day on the run up to World Penguin Day on the 25th April) at daily.zooniverse.org.
The world's largest and most popular platform for people-powered research. This research is made possible by volunteers—millions of people around the world who come together to assist professional researchers.