In our Who’s who in the Zoo blog series we introduce you to some of the people behind the Zooniverse. This week, meet Maysa, a developer in our Oxford team
– Helen
Name: Maysa Bashraheel
Location: Oxford University, but based in Manchester.
Tell us about your role within the team
This is my third week! I am the Zooniverse Developer Intern.
What did you do in your life before the Zooniverse?
About 4 weeks ago I was still a science teacher at a secondary school in Manchester – I came to my role after spending the last couple of years dabbling in coding and building stuff. I only realised I could potentially make a career out of a hobby in January. In a past life I was a Research Scientist for the Manchester Collaborative Centre for Inflammation Research (MCCIR) and specialised in Immunology with a focus on Transplants and specifically the heart. My bachelors is in Biomedical Science and I have a postgraduate degree in Education.
What does your typical working day involve?
Currently, I am learning a lot, I spend a lot of time familiarising myself with the codebase that makes up the Zooniverse. I am attempting to solve some issues, asking a million questions and exploring.
How would you describe the Zooniverse in one sentence?
The Zooniverse is a nurturing organisation that is committed to radical transparency and connects people from all corners of the world.
Tell us about the first Zooniverse project you were involved with
I think it was Beluga Bits! But I really have been fascinated by the Dental Disease projects and some of the interesting work around Etch-A-Cell. I think I have a thing for drawing projects.
Of all the discoveries made possible by the Zooniverse, which for you has been the most notable?
The TESS Planet Hunters discovery planetary systems was cool. My personal favourite is the Galaxy Zoo discovery of Pea Galaxies (a class of compact extremely star-forming galaxies that look like green peas!)
What’s been your most memorable Zooniverse experience?
So far, the 2022 Zooniverse Team Meeting. Truly a wonderful and productive and just overall exciting experience.
What are your top three citizen science projects?
The Big Sleep Survey, Parasite Safari, Stall Catchers.
What advice would you give to a researcher considering creating a Zooniverse project?
The volunteers are your biggest asset!
Where do you hope citizen science and the Zooniverse will be in 10 years time?
I’m hoping it will be a part of the Education system in a massive way. I would love if homework for students outlined contributing to a citizen science project and the curriculum actively involved scientists from a spectrum of backgrounds to inspire the future generation.
When not at work, where are we most likely to find you?
Hiking! My next hike will be up Snowdon in the dark so I can watch the sunrise.
This week meet Kat O’Brien Skerry, our Public Engagement Officer, who has been taking Zooniverse projects into schools around the UK.
– Helen
Name: Kat O’Brien Skerry
Location: University of Oxford, UK
Tell us about your role within the team
I joined the team in January 2022 as a Public Engagement Officer and I work on a fixed term contract bringing the Zooniverse to schools and educational settings around the country.
What did you do in your life before the Zooniverse?
My background is in STEM education having originally trained as a physics and maths teacher. I moved from there into informal education and most recently spent 5 years at the science museum in London in their learning team.
What does your typical working day involve?
My role is split between delivering workshops in schools and developing those workshops and convincing schools that they’re a great idea. So some days, I will be in classroom leading hands on activities, getting kids stuck into the Zooniverse, or facilitating zoom calls with the researchers. Some days I will be trying out experiments and explanations on anybody who I can find who appears (reasonably) willing to play. Some days I have a bit more of an office life and I’ll be finessing what we’ve done, contacting schools and all that stuff..
How would you describe the Zooniverse in one sentence?
A one stop shop for citizen science.
Tell us about the first Zooniverse project you were involved with
I first used Galaxy Zoo as an activity in a STEM club that I was running and had just as much fun playing as the kids did. Being added as an editor on projects so that I could take on this role was pretty terrifying!
What’s been your most memorable Zooniverse experience?
The feedback from one of my most recent schools was just the best. I had one pupil ask me, wide-eyed, “Did I really do actual science?” and respond to my “Of course you did!” with “Wow, maybe I could be a scientist”. I could have cried. To me, Zooniverse is a way to get kids to see themselves as scientists and seeing that impact becoming real is wonderful.
What are your top three citizen science projects?
I’m biased by the two I work on, so Galaxy Zoo and Science Scribbler: Virus Factory. But I also have a real soft spot for the Davy Notebooks Project because I’m a big history of science fan.
What advice would you give to a researcher considering creating a Zooniverse project?
Again, I’m biased, but think about if it could be useful in outreach!
How can someone who’s never contributed to a citizen science project get started?
Give it a go! There are so many great projects out there from annual birdwatching and insect hunts which you can do at home, to more supported projects in museums if you want a bit more help as you get started.
Where do you hope citizen science and the Zooniverse will be in 10 years time?
I’d love to see citizen science embraced as a way to make science education and outreach more meaningful for both schools and researchers, and Zooniverse as a means to do so.
When not at work, where are we most likely to find you?
I’m studying for an MA in Education at the moment (specialising in STEM education) so spend a lot of time in the library. Otherwise, I am found inexpertly herding and raising a small menagerie of children, chickens and chameleons.
Do you have any party tricks or hidden talents?
I can come up with a kid friendly STEM activity for almost anything. And will. Often without being asked.
In our Who’s who in the Zoo blog series we introduce you to some of the people behind the Zooniverse.
In this edition, meet Dr Mary Westwood, a recent addition to the Zooniverse team.
– Helen
Name: Mary Westwood
Location: University of Oxford, UK
Tell us about your role within the team
I joined the Zooniverse as a postdoctoral research assistant/project manager at the end of January 2022.
What did you do in your life before the Zooniverse?
I did a BSc and MSc in Biology at Wright State University in Ohio (where I’m from), then moved to the UK to do a PhD in Evolutionary Biology at the University of Edinburgh. Mostly I’m interested in how timing affects interactions between individuals, and towards the end of my PhD I started to dabble in bioacoustics and machine learning. Those last two topics are what led me to the Zooniverse.
What does your typical working day involve?
It varies a lot, but primarily I split my time between helping research teams get their projects up and running and doing my own research. I also get to write the weekly newsletters, which is a lot of fun.
How would you describe the Zooniverse in one sentence?
The innate curiosity and goodness of people put to very good use.
Tell us about the first Zooniverse project you were involved with
When I first checked out the Zooniverse, I wanted to see how bioacoustics projects were run on the platform. I can’t remember every project I looked into, but I do remember seeing HumBug and thinking what an incredible project it is.
Of all the discoveries made possible by the Zooniverse, which for you has been the most notable?
Research from the Penguin Watch team and volunteers has led to additional protections to marine protected areas, which is a really awesome outcome from a Zooniverse project.
What’s been your most memorable Zooniverse experience?
Best memory: all of the project launches, they’re a lot of fun.
Worst memory: mistakenly thinking I’d changed the background image of the entire Zooniverse website.
What are your top three citizen science projects?
I love them all equally.
What advice would you give to a researcher considering creating a Zooniverse project?
Just go for it. Start building a project, play around with setting up workflows. Delete them, start again. Don’t be afraid to reach out to us for help.
How can someone who’s never contributed to a citizen science project get started?
Browse which projects we’re hosting to see what sparks your interest. Download apps like iNaturalist and Merlin Bird ID – both awesome platforms which get you out into nature (win) and help science (double win).
Where do you hope citizen science and the Zooniverse will be in 10 years time?
Everywhere. Since discovering the Zooniverse, I can’t believe everyone doesn’t already know about it.
Is there anything in the Zooniverse pipeline that you’re particularly excited about?
I’m about to experience my first Zooniverse Team Meeting. Very excited to finally get together with all of the awesome people I’ve worked with remotely over the past six months.
When not at work, where are we most likely to find you?
Somewhere outdoors and with a pint, possibly also with a book or friends.
Do you have any party tricks or hidden talents?
My party trick is strong-arming any topic of conversation into a discussion about circadian rhythms.
You can check out Mary’s Zooniverse project here: The Cricket Wing
Our pilot-tested, research validated, Zooniverse-based activities for undergraduates are here and are ready for widespread use in your undergraduate science classrooms! These activities are 75-90 minutes long and are intended for use in introductory, undergraduate courses for non-science majors (or upper-level high school courses). These activities have been developed for use in either in-person courses or online courses through Google Docs.
In this activity, students learn about kelp forests in Tasmania in order to conduct an investigation into how marine ecosystems are impacted by small increases in ocean warming. Students use data generated by fellow citizen scientists in order to see how climate change has affected kelp forests specifically in Tasmania, Australia. In part one, students interpret graphs to draw conclusions about the relationship between greenhouse gas emissions and temperature, as well as learn about long term trends in Earth’s climate. Part two is intended to familiarize students with the Floating Forests platform. First, students practice classifying on a curated image set with a corresponding answer key. They will then be tasked with classifying images on the actual Floating Forests project. Part three uses data gathered by Floating Forests volunteers to introduce Tasmania, Australia as a case study of an ecosystem affected by climate change.
This is another three-part activity where students learn about the discovery and characterization of planetary systems outside of our Solar System.
In part one, students use a lecture tutorial-style approach to learn about planetary transits and transit light curves. Students learn how important planetary properties such as orbital period and size can be approximated from specific features in a transit light curve. In the second part of this activity, students practice identifying transits (or dips) in a curated set of actual light curves. They will then receive feedback regarding whether or not they identified the transits successfully. Once the students have practiced, they classify on Planet Hunters – TESS, the current iteration of the Planet Hunters Project. Students get the opportunity to observe actual TESS light curves, and help the Planet Hunters research team identify potential planetary transits in those light curves. Finally, the activity concludes with a data driven investigation where students are presented with the complex research question, ‘Is our Solar System unique?’, and they will have to interpret data representations derived from the NASA Exoplanet Archive to form their own conclusion.
A Little More About These Activities…
The Floating Forests and Planet Hunters-based classroom activities have been pilot tested with nearly 3,000 students across 14 colleges and universities. Survey data collected from participating students showed that completing either one of these two activities had statistically significant (positive) impacts on students’ ability to use data and evidence to answer scientific questions, on their ability to contribute in a meaningful way to science, and on their understanding that citizen science is a valuable tool that can be used to increase engagement in science. More than 70% of students claimed that these activities inspired them to come back and classify on additional Zooniverse projects! The results of these findings are being published in the Astronomy Education Journal (Simon et al., 2022, in review) and the Journal of Geophysics Education (Rosenthal et al., 2022, in prep).
Additional feedback from pilot instructors indicated that these activities were easy to implement into new or existing introductory science courses. A few of our favorite instructor comments:
“Being able to see and analyze the data and help with the entire research analysis process – students were very interested in that. They appreciated that it was real data. This is a real research project.”
“Well, there’s not enough time for me to say all the good things that I could say about Zooniverse. I think the benefit to the community, just the broader public, has been enormous. So I think these activities are fantastic, and sharing them, not only with colleges, but with high school and middle school educators, I think would be really beneficial. They’re fantastic.”
The full activities and corresponding activity-synopses are available on the Zooniverse Classrooms Page (https://classroom.zooniverse.org)! The development and assessment of these activities were part of a larger NSF-funded effort, Award #1821319, Engaging Non-Science Majors in Authentic Research through Citizen Science. A final activity based around the Zooniverse project Planet Four will be coming soon!
Also at classroom.zooniverse.org are two additional sets of materials, created through previous efforts:
Wildcam Labs
Designed for 11-13 year olds
The interactive map allows you to explore trail camera data and filter and download data to carry out analyses and test hypotheses.
An example set of lessons based around Wildcam Labs, focused on using wildlife camera citizen science projects to engage students in academic language acquisition
Funded by HHMI and the San Diego Zoo
Astro101 with Galaxy Zoo
Designed for undergraduate non-major introductory astronomy courses
Students learn about stars and galaxies through 4 half-hour guided activities and a 15-20 hour research project experience in which they analyze real data (including a curated Galaxy Zoo dataset), test hypotheses, make plots, and summarize their findings.
Funded by NSF
For both Wildcam Labs and Astro101 with Galaxy Zoo, instructors can set up private classrooms, invite students to join, curate data sets, and access guided activities and supporting educational resources.
Science Scribbler: Key2Cat Update from Nanoparticle Picking Workflow
Hi!
This is the Science Scribbler Team with some exciting news from our latest project: Key2Cat! We have been blown away by the incredible support of this community – hundreds of you have taken part in the Key2Cat project (https://www.zooniverse.org/projects/msbrhonclif/science-scribbler-key2cat) and helped to pick nanoparticles in our electron microscopy images of catalyst nanoparticles. In just 1 week, over 50,000 classifications were completed on 10,000 subjects and 170,000 nanoparticles and clusters were found!
Thank you for this huge effort!
We went through the data and prepared everything for the next step: classification. Getting the central coordinates of our nanoparticles and clusters with the correct class will allow us to improve our deep learning approach. But before getting into the details of the next steps, let’s recap what has been done so far using the gold on germanium (Au/Ge) data as an example.
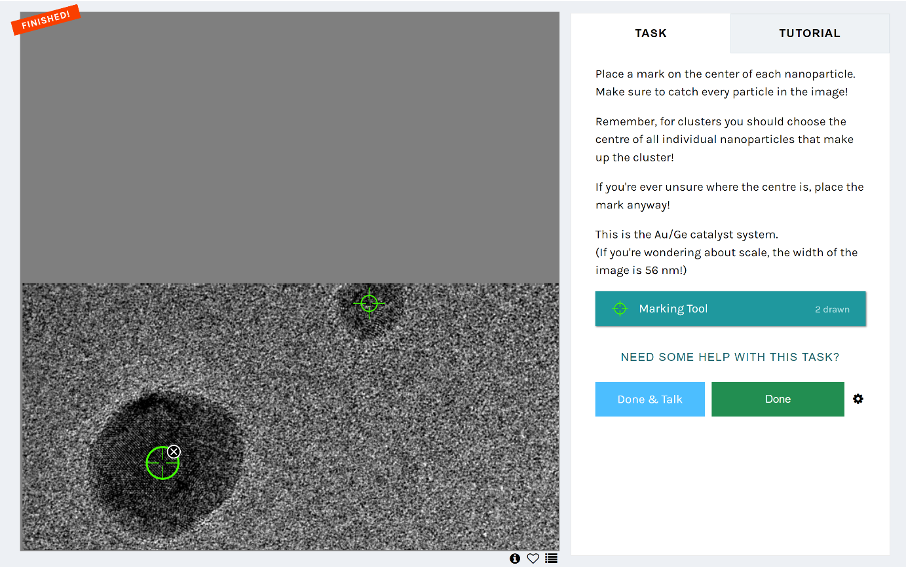
PICKING CATALYST PARTICLES
In the first workflow, you were asked to pick out both nanoparticles and clusters using a marking tool, which looked something like this:
As you might have realized, each of the images was only a small piece of a whole image. We tiled the images so that they wouldn’t be so overwhelming and time-consuming for an individual volunteer to work with. We also built in some overlap between the tiles so that if a nanoparticle fell on the edge in one image, it would be in the centre in another. Each tile was then shown to 5 different volunteers so that we could form a consensus on the centres of nanoparticles and clusters.
CRUNCHING THROUGH THE DATA
With your enormous speed, the whole Au/Ge dataset (94 full size images) was classified in just a few days! We have collected all of your marks and sorted them into their corresponding tiles. If we consider just a single tile that has been looked at by 5 volunteers, this is what the output data looks like:
With some thinking and coding we can recombine all the tiles that make up a single image, including the marks placed by all volunteers that contributed to the image:
Recontructed marked image
Wow, you all are really good at picking out the catalyst particles! Seeing how precisely all centres have been picked out in this visualisation is quite impressive. You may notice that there are more than 5 marks per nanoparticle – this is because of the overlap that we mentioned earlier. When taking the overlap into consideration, this means that each nanoparticle should be seen (at least partially!) by 20 volunteers.
The next step is to combine all of the marks to find a consensus centre point for each nanoparticle so that we have one set of coordinates to work with. There are numerous ways of doing this. One of the first that has given us good results is an unsupervised k-means algorithm [1]. This algorithm looks at all of the marks on the image and tries to find clusters of marks that are close to each other. It then joins these marks up into a single mark by finding a weighted average of their placements. You can think of it like tug-of-war where the algorithm finds the centre point because more marks are pulling it there.
Reconstructed image with centroids of marks
As you can see, the consensus based on your marks almost perfectly points at the centres of individual nanoparticles or nanoparticle clusters. We don’t yet know from this analysis if the nanoparticle is a part of a cluster or not, and in some cases, we also get marks in areas which are not nanoparticles as shown in the orange and red boxes above. Since only small parts of the overall image were shown in the marking task, the artifact in the orange box was mistaken as a nanoparticle and in the case of the red box, there is a mark at the very edge and on a very small dot-like instance where some of you might have been suspicious about another nanoparticle. This is expected, especially since we asked volunteers to place marks if they were unsure – we wanted to capture all possible instances of nanoparticles in this first step!
REFINING THE DATA
This is the part where the second workflow comes into play. Using the marks from the first workflow, we createda new dataset showing just a small area around the mark to collect more information.In this workflow we ask a few questions to help identify exactly what we see at each of the marks
With this workflow, we hope to classify all the nanoparticles and clusters of both the Au/Ge and Pd/C catalyst systems, while potential false marks can be cleaned up! Once this is accomplished, we’ll have all the required inputs to improve our deep learning approach.
Viewing the aurora in person is a magnificent experience, but due to location (or pesky clouds) it’s not always an option. Fortunately, citizen science projects like Aurorasaurus and Zooniverse’s Aurora Zoo make it easy to take part in aurora research from any location with an internet connection.
The Aurorasaurus Ambassadors group was excited to celebrate Citizen Science Month by inviting Dr. Daniel Whiter of Aurora Zoo to speak at our April meeting. In this post we bring you the highlights of his presentation, which is viewable in full here.
To ASK the Sky for Knowledge
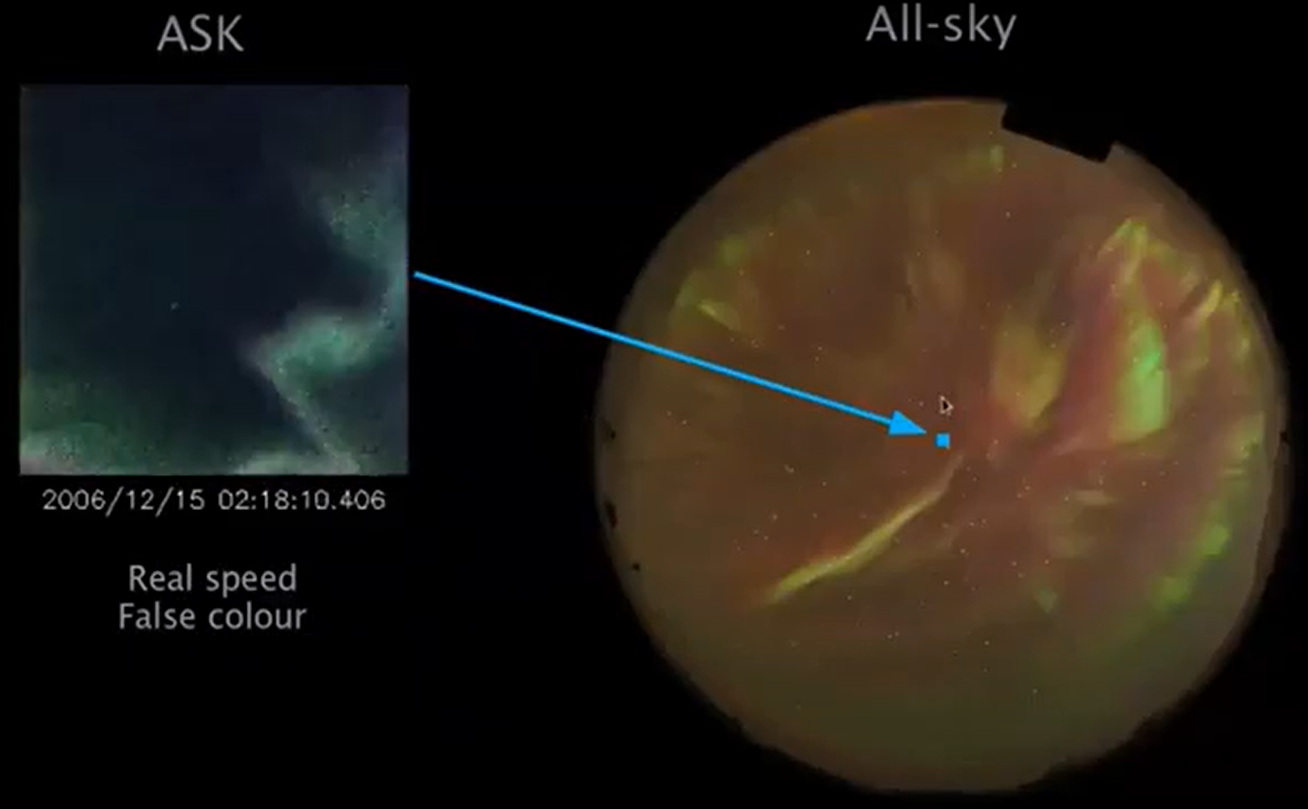
Far to the north on the Norwegian island of Svalbard, three very sensitive scientific cameras gaze at a narrow patch of sky. Each camera is tuned to look for a specific wavelength of auroral light, snapping pictures at 20 or 32 frames per second. While the cameras don’t register the green or red light that aurora chasers usually photograph, the aurora dances dynamically across ASK’s images. Scientists are trying to understand more about what causes these small-scale shapes, what conditions are necessary for them to occur, and how energy is transferred from space into the Earth’s atmosphere. ASK not only sees night-time aurora, but also special “cusp aurora” that occur during the day but are only visible in extremely specific conditions (more or less from Svalbard in the winter.)
Still from Dr. Whiter’s presentation. The tiny blue square on the allsky image (a fisheye photo looking straight up) represents the field of view of the ASK cameras. The cameras point almost directly overhead.
The setup, called Auroral Structure and Kinetics, or ASK, sometimes incorporates telescopes, similar to attaching binoculars to a camera. Project lead Dr. Daniel Whiter says, “The magnification of the telescopes is only 2x; the camera lenses themselves already provide a small field of view, equivalent to about a 280mm lens on a 35mm full frame camera. But the telescopes have a large aperture to capture lots of light, even with a small field of view.”
The challenge is that ASK has been watching the aurora for fifteen years and has amassed 180 terabytes of data. The team is too small to look through it all for the most interesting events, so they decided to ask for help from the general public.
Visiting the Aurora Zoo
Using the Zooniverse platform, the Aurora Zoo team set up a project with which anyone can look at short clips of auroras to help highlight patterns to investigate further. The pictures are processed so that they are easier to look at. They start out black and white, but are given “false color” to help make them colorblind-friendly and easier for citizen scientists to work with. They are also sequenced into short video clips to highlight movement. To separate out pictures of clouds, the data is skimmed by the scientists each day and run through an algorithm.
Aurora Zoo participants are then asked to classify the shape, movement, and “fuzziness,” or diffuse quality, of the aurora. STEVE fans will be delighted by the humor in some of the options! For example, two of the more complex types are affectionately called “chocolate sauce” and “psychedelic kaleidoscope.” So far, Aurora Zoo citizen scientists have analyzed 7 months’ worth of data out of the approximately 80 months ASK has been actively observing aurora. Check out Dr. Whiter’s full presentation for a walkthrough on how to classify auroras, and try it out on their website!
Some of the categories into which Zooniverse volunteers classify auroral movement. Credit: Dr. Daniel Whiter.
What can be learned from Aurora Zoo is different from other citizen science projects like Aurorasaurus. For example, when several arc shapes are close to one another, they can look like a single arc to the naked eye or in a photo, but the tiny patch of sky viewed through ASK can reveal them to be separate features. These tiny details are also relevant to the study of STEVE and tiny green features in its “picket fence”.
Early (Surprising!) Results
Aurora Zoo participants blew through the most recent batch of data, and fresh data is newly available. The statistics they gathered show that different shapes and movements occur at different times of day. For example, psychedelic kaleidoscopes and chocolate sauce are more common in the evening hours. The fact that the most dynamic forms show up at night rather than in the daytime cusp aurora reveals that these forms must be connected to very active aurora on the night side of the Earth.
Aurora Zoo participants also notice other structures. Several noted tiny structures later termed “fragmented aurora-like emissions,” or FAEs. Because of the special equipment ASK uses, the team was able to figure out that the FAEs they saw weren’t caused by usual auroral processes, but by something else. They published a paper about it, co-authored with the citizen scientists who noticed the FAEs.
Still from Dr. Whiter’s presentation, featuring FAEs and Aurora Zoo’s first publication.
What’s next? Now that Aurora Zoo has a lot of classifications, they plan to use citizen scientists’ classifications to train a machine learning program to classify more images. They also look forward to statistical studies, and to creating new activities within Aurora Zoo like tracing certain shapes of aurora.
STEVE fans, AuroraZoo hasn’t had a sighting yet. This makes sense, because ASK is at a higher latitude than that at which STEVE is usually seen. However, using a similar small-field technique to examine the details of STEVE has not yet been done. It might be interesting to try and could potentially yield some important insights into what causes FAEs.
Citizen Science Month, held during April of each year, encourages people to try out different projects. If you love the beautiful Northern and Southern Lights, you can help advance real aurora science by taking part in projects like Aurora Zoo and Aurorasaurus.
About the authors of this blog post: Dr. Liz MacDonald and Laura Brandt lead a citizen science project called Aurorasaurus. While not a Zooniverse project, Aurorasaurus tracks auroras around the world via real-time reports by citizen scientist aurora chasers on its website and on Twitter. Aurorasaurus also conducts outreach and education across the globe, often through partnerships with local groups of enthusiasts. Aurorasaurus is a research project that is a public-private partnership with the New Mexico Consortium supported by the National Science Foundation and NASA. Learn more about NASA citizen science here.
Engaging Faith-based Communities in Citizen Science through Zooniverse was an initiative designed to broaden participation in people-powered research (also referred to as citizen science) among religious and interfaith communities by helping them to engage with science through Zooniverse. Citizen science is a powerful way to build positive, long-term relationships across diverse communities by “putting a human face” on science and scientists. Participating in real scientific research is a great way to learn about the process of science as well as the scientists who conduct research.
The Engaging initiative provided models for how creative partnerships can be formed between scientific and religious communities that empower more people to become collaborators in the quest for knowledge. It included integrating Zooniverse projects into seminary classes as well as adult, youth, and intergenerational programs of religious communities; and promoting Zooniverse among interfaith communities concerned with environmental justice. Among other things, the project’s evaluation highlighted the need for scientists to do a better job of engaging with religious audiences in order to address racial and gender disparities in science. I encourage Zooniverse research teams to check out the series of short videos recently released by the AAAS Dialogue on Science, Ethics, and Religion to help scientists engage more effectively with communities of faith. By interacting personally with these communities and helping to “put a human face” on science, you may not only increase participation in your research projects, but help in the effort to diversify science in general.
Despite the difficulties imposed by the pandemic, I’m encouraged by what the Engaging initiative achieved, and the possibilities for expanding its impact in the future! The summary article of this project was published on March 28, 2022 by the AAAS Dialogue on Science, Ethics, and Religion.
The project team thanks the Alfred P. Sloan Foundation for supporting this project. Any opinions, findings, or recommendations expressed are those of the project team and do not necessarily reflect the views of the Sloan Foundation.
In this blog post, I’ll describe a recent prototyping project we (Jim O’Donnell: front-end developer; Sam Blickhan: Project Manager) carried out with our colleagues at the British Library (Mia Ridge, who I’m also collaborating with on the Collective Wisdom project) to explore IIIF compatibility for the Zooniverse Project Builder. You can read Mia’s complimentary blog post here.
History & context
While Zooniverse supports projects working with a number of different data formats (aka ‘subjects’), including video and audio, far and beyond the most frequently used data are images. Images are easy enough to drag and drop into our simple uploader (a feature of the Project Builder for adding data to your project) to create groups of subjects, or subject sets. If you want to upload your subjects with their associated metadata, however, things become slightly more complex. A subject manifest is a data table that allows you to list image file names alongside associated metadata. By including a manifest with your images to upload, the metadata will remain associated with those images within the Zooniverse platform.
So, what happens if you already have a manifest? Can you upload any type of manifest into Zooniverse? What if you’re working with a specific set of standards?
IIIF (pronounced “triple eye eff”) stands for International Image Interoperability Framework. It is a set of standards for image and A/V delivery across the web, from servers to different web environments. It supports viewing of images as well as interaction, and uses manifests as a major structural component.
If you’re new to IIIF, that’s okay! To understand the work we did, you’ll need three IIIF definitions, all reproduced here from https://iiif.io/get-started/how-iiif-works/:
Manifest: the prime unit in IIIF which lists all the information that makes up a IIIF object. It communicates how to display your digital objects, and what information to display about them, including structure, to varying degrees of complexity as determined by the implementer. (For example, if the object is a book of illustrations, where each illustrated page is a canvas, and there is one specific order to the arrangement of those pages).
Canvas: the frame of reference for the display of your content, both spatial and temporal (just like a painting canvas for two-dimensional materials, or with an added time dimension for a/v content).
Annotation: a standard way to associate different types of content to whatever is on your canvas (such as a translation of a line or the name of a person in a photograph. In the IIIF model, images and other presentation content are also technically annotations onto a canvas). For more detail, see the Web Annotation Data Model.
What we did
For this effort, we worked with Mia and her colleagues at the British Library on an exploratory project to see if we could create a proof of concept for Zooniverse image upload and data export which was IIIF compatible. If successful, these two prototypes could then form the basis for an expanded effort. We used the British Library In The Spotlight Zooniverse project as a testing ground.
Data upload
First, we wanted to figure out a way to create a Zooniverse subject set from a IIIF manifest. We figured the easiest approach would be to use the manifest URL, so Jim built a tool that imports IIIF manifests via a URL pasted into the Project Builder (see image below).
This is an experimental feature, so it won’t show up in your Zooniverse project builder ‘Subject Sets’ page by default. If you want to try it out, you can preview the feature by adding subject-sets/iiif?env=production to your project builder URL. For example, if your project number is #xxx, you’d use the URL https://www.zooniverse.org/lab/xxx/subject-sets/iiif?env=production
To create a new subject set, you simply copy/paste the IIIF manifest URL into the box at the top of the image and click ‘Fetch Manifest’. The Zooniverse uploader will present a list of metadata fields from the manifest. The tick box column at the far right allows you to flag certain fields as ‘Hidden’, meaning they won’t be shown to volunteers in your project’s classification interface. Once you’ve marked everything you want to be ‘Hidden’, you click ‘Create a subject set’ to generate the new subject set from the IIIF manifest.
Export to manifest with IIIF annotations
In the second phase of this experiment, we explored how to export Zooniverse project results as IIIF annotations. This was trickier, because the Zooniverse classification model requires multiple classifications from different volunteers, which are then typically aggregated together after being downloaded from the platform.
To export Zooniverse results as IIIF annotations, therefore, we needed to include a step that runs the appropriate in-house offline aggregation code, then convert the data to the appropriate IIIF annotation format. Because the aggregation step is necessary to produce a single annotation per task, this step is project- and workflow-specific (whereas the IIIF Manifest URL upload works for all project types). For this effort, we tested annotation publishing on the In The Spotlight Transcribe Dates workflow, which uses a simple free-text entry task. The other In The Spotlight workflow has a slight more complex task structure (rectangle marking task + text entry sub-task), which we’re hoping to be able to add to the technical documentation soon.
Now, we need your feedback! The next steps for this work will include identifying community needs and interest – would you use these tools for your Zooniverse project? What features look useful (or less so)? Your feedback will help us determine our next steps. Mostly, we want to know who our potential audiences are, what task types they would most want to use, and what sort of comfort level they have, particularly when it comes to running the annotations code (from “This is great!” to “I don’t even know where to start!”). There are a lot of possible routes we could take from here, and we want to make sure our future work is in service of our project building community.
Try out the In The Spotlight project and help create real data for testing ingest processes.
Mia and I are also part of the IIIF Slack community, so feel free to ping us there.
Finally, a massive “Thank you!” to the British Library for funding this experiment, and to Glen Robson and Josh Hadro at IIIF for their feedback on various stages of this experiment.
The Zooniverse team in Oxford, UK, is looking for a web developer intern to join us in summer 2022. If you’re looking to learn how to build websites and apps with a team of friendly developers, or if you just want an opportunity to flex your extant coding skills in an environment that loves scientific curiosity, then come have some tea with us!
The team here in the Zooniverse want to welcome more folks into the world of software development, and in turn, we want to learn from the unique ideas and experiences you can share.
The time has come to announce the winners of Grant’s Great Leaving Challenge! Many thanks to all who submitted classifications for our four featured projects over the past week. Your efforts have absolutely wowed us at the Zooniverse – not only did you meet the 100,000 classifications goal, you blew right through it. All in all, you submitted a whopping 293,692 classifications – nearly 3x our goal!
This classification challenge was a massive push forward for the projects involved, and the research teams are incredibly grateful. Grant himself was touched – he had this to say about the results of his namesake challenge:
“Over the last decade I’ve constantly been blown away by the amazing effort and commitment from Zooniverse volunteers, and yet again they have surpassed all expectations! I want to thank them for all they have done, both for this challenge, and over the entire lifetime of the project. THANK YOU!”
Here’s some data to back up just how successful this challenge was:
Figure 1. The x-axes show each day the challenge ran, while the y-axes mark the percent change in classifications from the week prior. For example, this means that for Penguin Watch, there was a 100% increase in classifications on Tuesday March 22nd compared to Tuesday March 15th.
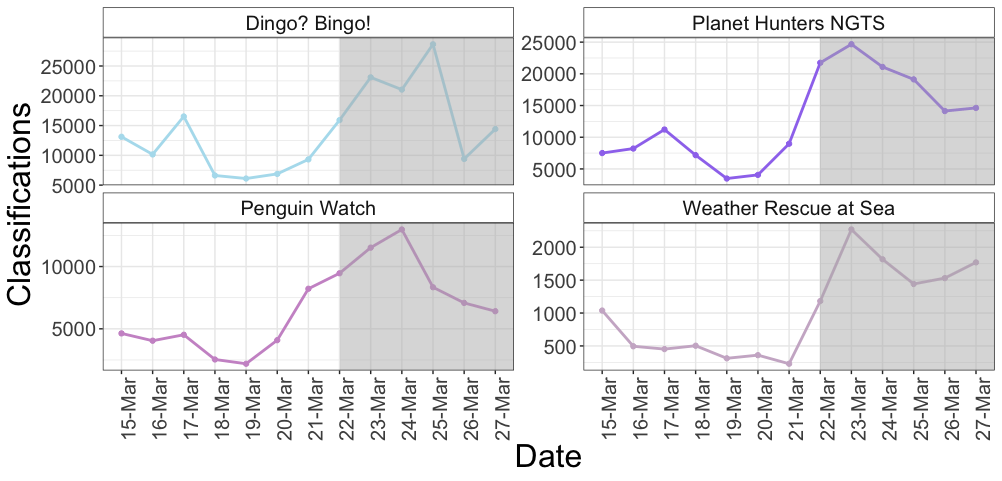
Figure 2. Here, each plot shows the date on the x-axis and the total number of classifications for that day on the y-axis. The shaded areas indicate which days were part of the challenge, and the non-shaded white areas prior are data from the preceding week. Note that the y-axes are unequal across plots because they’ve been scaled to fit their own data.
While, in this case, I do really think the figures speak for themselves, here are some highlights:
Just two days into the challenge, daily classifications for Dingo? Bingo! more than doubled compared to one week prior. A short two days later, they reached a 300% increase from the same day the previous week. All in all, Dingo? Bingo! volunteers submitted an incredible 112,505 classifications!
Planet Hunters NGTS volunteers rode a hefty 200% increase in classifications for the first two days of the challenge. On the fifth day, they peaked at an incredible 300% increase! Overall, volunteers submitted a whopping 115,388 classifications over the course of the 6 day challenge. Remarkable!
Penguin Watch volunteers readily doubled classifications from the week prior, with a peak on the fourth day when classifications were up more than 200% from the preceding week. By the end of the challenge, volunteers had submitted a grand total of 55,787 classifications!
On day two of the challenge, Weather Rescue at Sea volunteers submitted an astonishing 350% more classifications than one week prior. On the final two days of the challenge, classifications were up by nearly 400% from the preceding week! Overall, volunteers submitted an awesome 10,012 classifications.
When pulling together this data, we were just absolutely amazed by how much effort the volunteers put into Grant’s Great Leaving Challenge. What an awesome example of the power of citizen science. From all of us at the Zooniverse and from the project teams who took part in the challenge – thank you. This has been such a fun way to send off Grant, who will be greatly missed by all!
The world's largest and most popular platform for people-powered research. This research is made possible by volunteers—millions of people around the world who come together to assist professional researchers.