

Since its founding, a well-known feature of the Zooniverse platform has been that volunteers see (& interact with) image, audio, or video files (known as ‘subjects’ in Zooniverse parlance) in an intentionally random order. A visit to help.zooniverse.org provides this description of the subject selection process:
[T]he process for selecting which subjects get shown to volunteers is very simple: it randomly selects an (unretired, unseen) subject from the linked subject sets for that workflow.
https://help.zooniverse.org/next-steps/subject-selection/
For some project types, this method can help to avoid bias in classification. For other project types, however, random subject delivery can make the task more difficult.
Transcription projects frequently use a single image as the subject-level unit. These images most often depict a single page of text (i.e., 1 subject = 1 image = 1 page of text). Depending on the source material being transcribed, that unit/page is often only part of a multi-page document, such as a letter or manuscript. In these cases, random subject delivery removes the subject (page) from its larger context (document). This can actually make successful transcription more difficult, as seeing additional uses of a word or letter can be helpful for deciphering a particular hand.
Decontextualized transcription can also be frustrating for volunteers who may want greater context for the document they’re working on. It’s more interesting to be able to read or transcribe an entire letter, rather than snippets of a whole.
This is why we’re exploring new approaches to subject delivery on Zooniverse as part of the Engaging Crowds project. Engaging Crowds aims to ‘investigate the practice of citizen research in the heritage sector‘ in collaboration with the UK National Archives, the Royal Botanic Garden Edinburgh, and the National Maritime Museum. The project is funded by the UK Arts & Humanities Research Council as one of eight foundational projects in the ‘Towards a National Collection: Opening UK Heritage to the World‘ program.
As part of this research project, we have designed and built a new indexing tool that allows volunteers to have more agency around which subject sets—and even which subjects—they want to work on, rather than receiving them randomly.
The indexing tool allows for a few levels of granularity. Volunteers can select what workflow they want to work on, as well as the subject set. These features are currently being used on HMS NHS: The Nautical Health Service, the first of three Engaging Crowds Zooniverse projects that will launch on the platform before the end of 2021.

Sets that are 100% complete are ‘greyed’ out, and moved to the end of the list — this feature was based on feedback from early volunteers who found it too easy to accidentally select a completed set to work on.
In the most recent iteration of the indexing tool, selection happens at the subject level, too. Scarlets and Blues is the second Engaging Crowds project, featuring an expanded indexing tool from the version seen in HMS: NHS. Within a subject set, volunteers can select the individual subject they want to work on based on the metadata fields available. Once they have selected a subject, they can work sequentially through the rest of the set, or return to the index and choose a new subject.
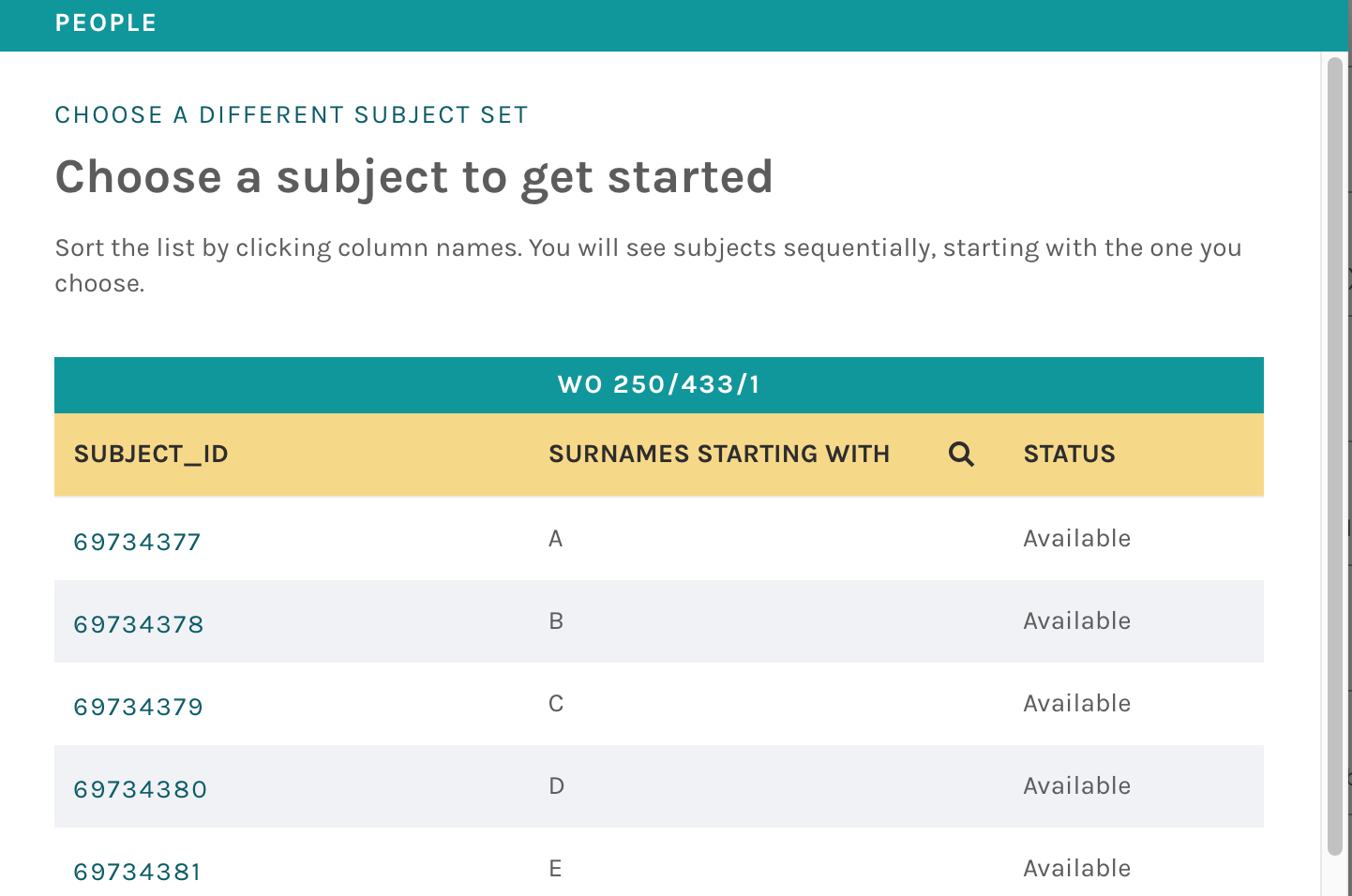
On all subject index pages, the Status column tells volunteers whether a subject is Available (i.e. not complete and not yet seen); Already Seen (i.e. not complete, but already classified by the volunteer viewing the list); or Finished (i.e. has received enough classifications and no longer needs additional effort).
A major new feature of the indexing tool is that completed subjects remain visible, so that volunteers can retain the context of the entire document. When transcribing sequentially through a subject set, volunteers that reach a retired subject will see a pop-up message over the classify interface that notes the subject is finished, and offers available options for how to move on with the classification task, including going directly to the next classifiable subject or returning to the index to choose a new subject to classify.

As noted above, sequential classification can help provide context for classifying images that are part of a group, but until now has not been a common feature of the platform. To help communicate ordered subject delivery to volunteers, we have included information about the subject set–and a given subject’s place within that set–in a banner on top of the image. This subject information banner (shown above) tells volunteers where they are within the order of a specific subject set.
Possible community use cases for the indexing tool might include volunteers searching a subject set in order to work on documents written by a particular author, written within a specific year, or that are written in a certain language. Some of the inspiration for this work came from Talk posts on the Anti-Slavery Manuscripts project, in which volunteers asked how they could find letters written by certain authors whose handwriting they had become particularly adept at transcribing. Our hope is that the indexing tool will help volunteers more quickly access the type of materials in a project that speak to their interests or needs.
If you have any questions, comments, or concerns about the indexing tool, please feel free to post a comment here, or on one of our Zooniverse-wide Talk boards. This feature will not be immediately available in the Project Builder, but project teams who are interested in using the indexing tool on a future project should email contact@zooniverse.org and use ‘Indexing Tool’ in the subject line. We’re keen to continue trying out these new tools on a range of projects, with the ultimate goal of making them freely available in the Project Builder.
Frequently Asked Questions: Indexing Tool + Sequential Classification
“Will all new Zooniverse projects use this method for subject selection and sequential classification?”
No. The indexing tool is an optional feature. Teams who feel that their projects would benefit from this feature can reach out to us for more information about including the indexing tool in their projects. Those who don’t want the indexing tool will be able to carry on with random subject delivery as before.
“Why can’t I refresh the page to get a new subject?”
Projects that use sequential classification do not support loading new subjects on page refresh. If the project is using the indexing tool, you’ll need to return to the index and choose a new page. If the project is not using the indexing tool, you’ll need to classify the image in order to move forward in the order of sequence. However, the third Engaging Crowds project (a collaboration with the Royal Botanic Garden Edinburgh) will include the full suite of indexing tool features, plus an additional ‘pagination’ option that will allow volunteers to move forwards and backwards through a subject set to decide what to work on see preview image below). We’ll write a follow-up to this post once that project has launched.

“How do I know if I’m getting the same page again?”
The subject information banner will give you information about where you are in a subject set. If you think you’re getting the same subject twice, first start by checking the subject information banner. If you still think you’re getting repeat subjects, send the project team a message on the appropriate Talk board. If possible, include the information from the subject information banner in your post (e.g. “I just received subject 10/30 again, but I think I already classified it!”).

I’m certainly not a fan of wandering around the data to decide what you want to do. I like a sequential approach which makes sense, to me anyway. I can’t see many good results for this method.
Hi Jacqueline,
Thanks for weighing in. The indexing tool does actually include sequential classification, so someone who isn’t interested in picking what they’d like to work on can simply choose to start at the first subject in a set and then work through the rest of the set in sequence, without having to select every time. We’re aware that new approaches won’t please everyone, so we aim to design a range of classification approaches that research teams can choose to use (or not) based on their research goals as well as the preferences of their volunteer communities. If you’re not a fan of the method, there will certainly be plenty of other Zooniverse projects to participate in which use the traditional method of random subject delivery.
Best wishes,
Sam
I’ll certainly give it a try. Who knows, it might be just as good or better than the other methods.