Last month I gave a talk at the Wetton Workshop in Oxford. Unlike the other talks that week, mine wasn’t about astronomy. I was talking about Docker – a useful tool which has become popular among people who run web services. We use it for practically everything here, and it’s pretty clear that researchers would find it useful if only more of them used it. That’s especially true in fields like astronomy, where a lot of people write their own code to process and analyse their data. If after reading this post you think you’d like to give Docker a try and you’d like some help getting started, just get in touch and I’ll be happy to help.
I’m going to give a brief outline of what Docker is and why it’s useful, but first let’s set the scene. You’re trying to run a script in Python that needs a particular version of NumPy. You install that version but it doesn’t seem to work. Or you already have a different version installed for another project and can’t change it. Or the version it needs is really old and isn’t available to download anymore. You spend hours installing different combinations of packages and eventually you get it working, but you’re not sure exactly what fixed it and you couldn’t repeat the same steps in the future if you wanted to exactly reproduce the environment you’re now working in.
Many projects require an interconnected web of dependencies, so there are a lot of things that can go wrong when you’re trying to get everything set up. There are a few tools that can help with some of these problems. For Python you can use virtual environments or Anaconda. Some languages install dependencies in the project directory to avoid conflicts, which can cause its own problems. None of that helps when the right versions of packages are simply not available any more, though, and none of those options makes it easy to just download and run your code without a lot of tedious setup. Especially if the person downloading it isn’t already familiar with Python, for example.
If people who download your code today can struggle to get it running, how will it be years from now when the version of NumPy you used isn’t around anymore and the current version is incompatible? That’s if there even is a current version after so many years. Maybe people won’t even be using Python then.
Luckily there is now a solution to all of this, and it’s called software containers. Software containers are a way of packaging applications into their own self-contained environment. Everything you need to run the application is bundled up with the application itself, and it is isolated from the rest of the operating system when it runs. You don’t need to install this and that, upgrade some other thing, check the phase of the moon, and hold your breath to get someone’s code running. You just run one command and whether the application was built with Python, Ruby, Java, or some other thing you’ve never heard of, it will run as expected. No setup required!
Docker is the most well-known way of running containers on your computer. There are other options, such as Kubernetes, but I’m only going to talk about Docker here.
Using containers could seriously improve the reproducibility of your research. If you bundle up your code and data in a Docker image, and publish that image alongside your papers, anyone in the world will be able to re-run your code and get the same results with almost no effort. That includes yourself a few years from now, when you don’t remember how your code works and half of its dependencies aren’t available to install any more.
There is a growing movement for researchers to publish not just their results, but also their raw data and the code they used to process it. Containers are the perfect mechanism for publishing both of those together. A search of arXiv shows there have only been 40 mentions of Docker in papers across all fields in the past year. For comparison there have been 474 papers which mention Python, many of which (possibly most, but I haven’t counted) are presenting scripts and modules created by the authors. That’s without even mentioning other programming languages. This is a missed opportunity, given how much easier it would be to run all this code if the authors provided Docker images. (Some of those authors might provide Docker images without mentioning it in the paper, but that number will be small.)
Docker itself is open source, and all the core file formats and designs are standardised by the Open Container Initiative. Besides Docker, other OCI members include tech giants such as Amazon, Facebook, Microsoft, Google, and lots of others. The technology is designed to be future proof and it isn’t going away, and you won’t be locked into any one vendor’s products by using it. If you package your software in a Docker container you can be reasonably certain it will still run years, or decades, from now. You can install Docker for free by downloading the community edition.
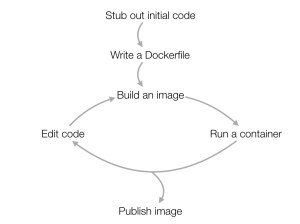 So how might Docker fit into your workday? Your development cycle will probably look something like this: First you’ll probably outline an initial version of the code, and then write a Dockerfile containing the instructions for installing the dependencies and running the code. Then it’s basically the same as what you’d normally do. As you’re working on the code, you’d iterate by building an image and then running that image as a container to test it. (With more advanced usage you can often avoid building a new image every time you run it, by mounting the working directory into the container at runtime.) Once the code is ready you can make it available by publishing the Docker image.
So how might Docker fit into your workday? Your development cycle will probably look something like this: First you’ll probably outline an initial version of the code, and then write a Dockerfile containing the instructions for installing the dependencies and running the code. Then it’s basically the same as what you’d normally do. As you’re working on the code, you’d iterate by building an image and then running that image as a container to test it. (With more advanced usage you can often avoid building a new image every time you run it, by mounting the working directory into the container at runtime.) Once the code is ready you can make it available by publishing the Docker image.
There are three approaches to publishing the image: push the image to the Docker Hub or another Docker registry, publish the Dockerfile along with your code, or export the image as a tar file and upload that somewhere. Obviously these aren’t mutually exclusive. You should do at least the first two, and it’s probably also wise to publish the tar file wherever you’d normally publish your data.
The Docker Hub is a free registry for images, so it’s a good place to upload your images so that other Docker users can find them. It’s also where you’ll find a wide selection of ready-built Docker images, both created by the Docker project themselves and created by other users. We at the Zooniverse publish all of the Docker images we use for our own work on the Docker Hub, and it’s an important part of how we manage our web services infrastructure. There are images for many major programming languages and operating system environments.
There are also a few packages which will allow you to run containers in high performance computing environments. Two popular ones are Singularity and Shifter. These will allow you to develop locally using Docker, and then convert your Docker image to run on your HPC cluster. That means the environment it runs in on the cluster will be identical to your development environment, so you won’t run into any surprises when it’s time to run it. Talk to your institution’s IT/HPC people to find out what options are available to you.
Hopefully I’ve made the case for using Docker (or containers in general) for your research. Check out the Docker getting started guide to find out more, and as I said at the beginning, if you’re thinking of using Docker in your research and you want a hand getting started, feel free to get in touch with me and I’ll be happy to help you.