The following post is by Dr Brooke Simmons, who has been leading the Zooniverse efforts to help in the aftermath of the recent Caribbean storms.
This year has seen a particularly devastating storm season. As Hurricane Irma was picking up steam and moving towards the Caribbean, we spoke to our disaster relief partners at Rescue Global and in the Machine Learning Research Group at Oxford and decided to activate the Planetary Response Network. We had previously worked with the same partners for our responses to the Nepal and Ecuador earthquakes in 2015 and 2016, and this time Rescue Global had many of the same needs: maps of expected and observed damage, and identifications of temporary settlements where displaced people might be sheltering.
The Planetary Response Network is a partnership with many people and organizations and which uses many sources of data; the Zooniverse volunteers are at its heart. The first cloud-free data available following the storm was of Guadeloupe, and our community examined pre-storm and post-storm images, marking building damage, flooding, impassable roads and signs of temporary structures. The response to our newsletter was so strong that the first set of data was classified in just 2 hours! And as more imaging has become available, we’ve processed it and released it on the project. By the time Hurricane Maria arrived in the Caribbean, Zooniverse volunteers had classified 9 different image sets from all over the Caribbean, additionally including Turks and Caicos, the Virgin Islands (US and British), and Antigua & Barbuda. That’s about 1.5 years’ worth of effort, if it was 1 person searching through these images as a full-time job. Even with a team of satellite experts it would still take much longer to analyze what the Zooniverse volunteers collectively have in just days. And there’s still more imaging: the storms aren’t over yet.
We’ve been checking in every day with Rescue Global and our Machine Learning collaborators to get feedback on how our classifications are being used and to refresh the priority list for the next set of image targets. As an example of one of those adjustments, yesterday we paused the Antigua & Barbuda dataset in order to get a rapid estimate of building density in Puerto Rico from images taken just before Irma and Maria’s arrival. We needed those because, while the algorithms used to produce the expected damage maps do incorporate external data like Census population counts and building information from OpenStreetMaps, some of that data can be incomplete or out of date (like the Census, which is an excellent resource but which is many years old now). Our volunteers collectively provided an urgently needed, uniformly-assessed and up-to-date estimate across the whole island in a matter of hours — and that data is now being used to make expected damage maps that will be delivered to Rescue Global before the post-Maria clouds have fully cleared.
Even though the project is still ongoing and we don’t have full results yet, I wanted to share some early results of the full process and the feedback we’ve been getting from responders on the ground. One of our earliest priorities was St. Thomas in the USVI, because we anticipated it would be damaged but other crowdsourcing efforts weren’t yet covering that area. From your classifications we made a raw map of damage markings. Here’s structural damage:
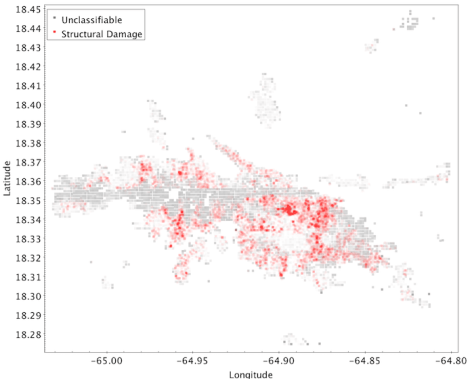
The gray stripe was an area of clouds and some artifacts. You can get an idea from this of where there is significant damage, but it’s raw and still needs further processing. For example, in the above map, damage marked as “catastrophic” is more opaque so will look redder, but more individual markings of damage in the same place will also stack to look redder, so it’s hard to tell the difference in this visualization between 1 building out of 100 that’s destroyed and 100 buildings that all have less severe damage. The areas that had clouds and artifacts also weren’t completely unclassifiable, so there are still some markings in there that we can use to estimate what damage might be lurking under the clouds. Our Machine Learning partners incorporate these classifications and the building counts provided by our project as well as by OpenStreetMaps into a code that produces a “heat map” of structural damage that helps responders understand the probability and proportion of damage in a given area as well as how bad the damage is:
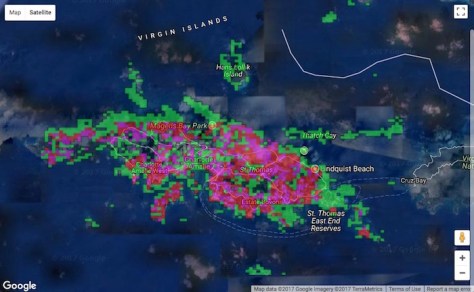
In the heat map, the green areas are where some damage was marked, but at a low level compared to how many buildings are in the area. In the red areas, over 60% of the buildings present were marked as damaged. (Pink areas are intermediate between these.)
With volunteer classifications as inputs, we were able to deliver maps like this (and similar versions for flooding, road blockage, and temporary shelters) for every island we classified. We also incorporated other efforts like those of Tomnod to map additional islands, so that we could keep our focus on areas that hadn’t yet been covered while still providing as much accurate information to responders as possible.
Feedback from the ground has been excellent. Rescue Global has been using the maps to help inform their resource allocation, ranging from where to deliver aid packages to where to fly aerial reconnaissance missions (fuel for flights is a precious commodity, so it’s critical to know in advance which areas most need the extra follow-up). They have also shared the heat maps with other organizations providing response and aid in the area, so Zooniverse volunteers’ classifications are having an extended positive effect on efforts in the whole region. And there has been some specific feedback, too. This message came several days ago from Rebekah Yore at Rescue Global:
In addition to supplying an NGO with satellite communications on St Thomas island, the team also evacuated a small number of patients with critical healthcare needs (including a pregnant lady) to San Juan. Both missions were aided by the heat maps.
To me, this illustrates what we can all do together. Everyone has different roles to play here, from those who have a few minutes a day to contribute to those spending hours clicking and analyzing data, and certainly including those spending hours huddled over a laptop in a temporary base camp answering our emailed questions about project design and priorities while the rescue and response effort goes on around them. Without all of them, none of this would be possible.
We’re still going, now processing images taken following Hurricane Maria. But we know it’s important that our community be able to share the feedback we’ve been receiving, so even though we aren’t finished yet, we still wanted to show you this and say: thank you.
Update:
Now that the project’s active response phase has completed, we have written a further description of how the maps our volunteers helped generate were used on the project’s Results page. Additionally, every registered volunteer who contributed at least 1 classification to the project during its active phase is credited on our Team page. Together we contributed nearly 3 years’ worth of full-time effort to the response, in only 3 weeks.
Further Acknowledgments
The Planetary Response Network has been nurtured and developed by many partners and is enabled by the availability of pre- and post-event imagery. We would like to acknowledge them:
- Firstly, our brilliant volunteers. To date on this project we have had contributions from about 10,000 unique IP addresses, of which about half are from registered Zooniverse accounts.
- The PRN has been supported by Imperative Space and European Space Agency as part of the Crowd4Sat programme. Any views expressed on this website shall in no way be taken to represent the official opinion of ESA.
- The development of the current Zooniverse platform has been supported by a Google Global Impact award and the Alfred P. Sloan Foundation.
- We are grateful to Patrick Meier and QCRI for their partnership in the development of PRN.
- We are grateful to those whose counsel (and data!) we have been fortunate to receive over the years: the Humanitarian OpenStreetMap Team, the Standby Task Force, Tomnod.
- We are grateful to our imagery providers:
- Planet has graciously provided images to the PRN in each of our projects. (Planet Team 2017 Planet Application Program Interface: In Space For Life on Earth. San Francisco, CA. https://api.planet.com, License: CC-BY-SA)
- DigitalGlobe provides high-resolution imagery as part of their Open Data Program (Creative Commons Attribution Non Commercial 4.0).
- Thanks to the USGS for making Landsat 8 images publicly available.
- Thanks to ESA for making Sentinel-2 images publicly available.
- Thanks to Amazon Web Services’ Open Data program for hosting Sentinel-2 and Landsat 8 images, both of which were used in this project (and sourced via AWS’ image browser and servers);
- We’d also like to thank several individuals:
- Everyone at Rescue Global, but particularly Hannah Pathak and Rebekah Yore for patiently answering our questions and always keeping the lines of communication open;
- Steve Reece in Oxford’s ML group for burning the midnight oil;
- The Zooniverse team members, who are absolute stars for jumping in and helping out at a moment’s notice.