This post is part of our Kavli Foundation-funded series, Ethical Considerations for Machine Learning in Public-Engaged Research. Read our project announcement blog post here.
We’d like to thank everyone who participated in the first of four surveys to help shape the future of AI and public-engaged research. We received over 1000 responses to the first survey, which informed priorities for the first workshop and helped Zooniverse leadership understand some of your interests, concerns, and ideas around this important topic.
Our second survey is launching today, and will be accepting responses through July 18th. We hope you will participate!
In case you missed it, check out the project announcement blog post to learn more about Zooniverse’s effort to develop recommendations for running AI-engaged projects on the Zooniverse platform.
Who is running this study? The Project Director is Dr. Samantha Blickhan, Zooniverse Co-Director and Digital Humanities Lead.
Who is funding this research? This research is funded by The Kavli Foundation.
How can I contact the team? Questions can be addressed to hillary@zooniverse.org or samantha@zooniverse.org
This guest post was written by the Davy Notebooks Project research team. It was updated on 21 October 2024 to include a link to the published transcription site.
The Davy Notebooks Project first launched as a pilot project in 2019. After securing additional funding and three months of testing and revision, the project re-launched in June 2021 in its current, ‘full’ iteration. And now it is drawing to a close.
Since April 2021, 11,991 pages of Davy’s manuscript notebooks have been transcribed – this, of course, is a major achievement. Adding the 1,130 pages transcribed during our pilot project, which launched in April 2019, brings the total up to 13,121 pages. Including Zooniverse beta test periods (during which time relatively few pages were made available to transcribe), this was achieved in a period of forty-one months; discounting beta test periods brings the total down to thirty-six months. At the time of writing, with the transcription of Davy’s 129 notebooks now complete, the Davy Notebooks Project has 3,649 volunteers from all over the world. 505 volunteers transcribed during our pilot project, so the full project attracted 3,144 transcribers.
The transition from the pilot build to the developed full project that, at its peak, was collecting up to 6,675 individual classifications per month, has been a steady learning experience. Samantha Blickhan’s article (co-authored by other members of the project team) in our special issue of Notes and Records of the Royal Society, ‘The Benefits of “Slow” Development: Towards a Best Practice for Sustainable Technical Infrastructure Through the Davy Notebooks Project’, charts the Davy Notebooks Project’s development, and makes a convincing case for the type of ‘slow’ development – or gradual improvement in response to feedback – approach that the project has taken.
While new notebooks were being released and transcribed on Zooniverse, the project’s editorial team were reviewing and editing the submitted transcriptions through Zooniverse’s ALICE (Aggregated Line Inspector and Collaborative Editor) app. The team were also engaging, daily, with our transcriber community on the project’s Talk boards – discussing particularly tricky or interesting passages in recently transcribed pages, sharing information and insights on the material being transcribed, and creating a repository of useful research that has been valuable in tracing connections throughout Davy’s textual corpus as a whole and in writing explanatory notes for the transcriptions. The current number of individual notes (repeated throughout the edition as necessary) stands at approximately 4,500.
Running a successful online crowdsourcing project requires effective two-way communication between the project team and the volunteer community. A series of ‘off Zooniverse’ volunteer-focused events offered the opportunity to engage with our volunteers, and – importantly – a venue to thank them for their continued, frequently excellent efforts in transcribing and interpreting Davy’s notebooks. Conference panels at large UK conferences with international representation (the British Society for Literature and Science conferences in 2022 and 2023, the British Association for Romantic Studies conference, jointly held with the North American Society for the Study of Romanticism, in 2022) enabled the project team to share their research-in-progress with the academic community, and our own conference, ‘Science and/or Poetry: Interdisciplinarity in Notebooks’, held at Lancaster University in July 2023, brought together scholars working on a diverse range of notebooks and other related manuscript materials to share our most recent insights and findings. Our monthly project team reading group, superbly organised by Sara Cole over several years, helped us to think about the organisation of Davy’s notebook collection as a whole, and created many a new research lead. Our travelling exhibition, which stopped at the Royal Institution, Northumberland County Hall, and Wordsworth Grasmere, has created new interest in Davy and his notebooks, and presented some of the key research findings of the project. All of these events fed directly into maintaining the momentum of the Davy Notebooks Project.
We are now moving towards the publication of the free-to-access digital edition of Davy’s whole notebook corpus that has been our goal since the start. Our digital edition will be hosted on the Lancaster Digital Collections platform, which is based on the well-established Cambridge Digital Library platform. View the Davy Notebooks transcription collection here: https://digitalcollections.lancaster.ac.uk/collections/davy/1.
Thankfully, we have benefited from the continued involvement, post-transcription, of a core of volunteer transcribers, who have taken on new responsibilities in assisting with the final editing of the notebooks; special thanks go to David Hardy (@deehar) and Thomas Schmidt (@plphy), who have helped to improve our transcriptions and notes in significant measure. We have also benefited at various points in the project from additional research assistance, from our UCL STS Summer Studentship project interns (Alexander Theo Giesen, Mandy Huynh, Stella Liu, Clara Ng, and Shreya Rana), from specialists in early nineteenth-century mathematics (Brigitte Stenhouse and Nicolas Michel), and from students and postgraduates in the Department of English Literature and Creative Writing at Lancaster University (Emma Hansen, Lee Hansen, Rebekah Musk, Frank Pearson, and Rebecca Spence), for which we are very grateful.
Work continues behind the scenes on finalising the transcriptions on LDC, and on the preparation of our forthcoming special issue of Notes and Records of the Royal Society, which is due to be published at the end of the year. Our digital edition will be officially launched at Lancaster Litfest on Saturday 19 October 2024. This will give us another opportunity to thank the thousands of volunteers who have made this work possible.
Truly, we could not have made the important advances in Davy scholarship that we have made since 2019 without every one of our volunteers, who gave freely and generously of their time and knowledge, and who hopefully enjoyed playing such a key role in a large research project – this is not only a social edition of Davy’s notebooks, but also, in large measure, their edition. Thank you all.
The Community Catalog (https://community-catalog.zooniverse.org) is a custom tool to offer Zooniverse project participants the opportunity to explore a project dataset, and to allow our team to experiment with creating new pathways into classifying.
We wanted to create a digital space that would facilitate not only sharing, but also discovery of participants’ contributions alongside institutional information (i.e. metadata) about the subjects being classified. The result was a data exploration app connected to specific Zooniverse crowdsourcing projects (How Did We Get Here?and Stereovision) that allows users to search and explore each project’s photo dataset based on participant-generated hashtags as well as the institutional metadata provided by project teams.
The Home Page of the Stereovision project in the Community Catalog.
The app includes a home page (shown above) with search/browsing capabilities, as well as an individual page for each photograph included in the project. The subject page (shown below) displays any available institutional metadata, participant-generated hashtags, and Talk comments. A ‘Classify this subject’ button allows users exploring the data to go directly to the Zooniverse project and participate in whatever type of data collection is taking place (transcription, labeling, generating descriptive text, etc.).
The Subject Page of the Community Catalog, displaying a subject with multiple Talk comments and community-generated hashtags.
Combined with the Talk (and QuickTalk) features, we’re hoping that this tool will encourage participants to share their experiences, memories, questions, and thoughts about the project photos, the historical events depicted, and the importance of the collection. The Community Catalog offers an approach where a participant can allow their interest in a specific item to lead them to take part in a classification task, rather than classification to Talk being a one-way street.
How Did We Get Here? was the pilot project for the Community Catalog, and is now complete. We have just launched the second project to use the Catalog, Stereovision, which you can participate in either via the Community Catalog site, or by visiting the Zooniverse project here: Stereovision.
The Community Catalog is not available for re-use by other projects in this exact form (i.e. as a standalone app), but we’re planning to incorporate some of its features into the Talk section of the Zooniverse platform in 2025. If you have any questions or would like to share your thoughts about this app, please feel free to reply to this post, or email us at contact@zooniverse.org.
The Community Catalog was developed as part of the AHRC-funded project Communities and Crowds. This project is run in collaboration with volunteer researchers and staff at the National Science and Media Museum in Bradford, United Kingdom, and National Museums Scotland, as well as with the Zooniverse teams at Oxford University and the Adler Planetarium in Chicago.
In this blog post, I’ll describe a recent prototyping project we (Jim O’Donnell: front-end developer; Sam Blickhan: Project Manager) carried out with our colleagues at the British Library (Mia Ridge, who I’m also collaborating with on the Collective Wisdom project) to explore IIIF compatibility for the Zooniverse Project Builder. You can read Mia’s complimentary blog post here.
History & context
While Zooniverse supports projects working with a number of different data formats (aka ‘subjects’), including video and audio, far and beyond the most frequently used data are images. Images are easy enough to drag and drop into our simple uploader (a feature of the Project Builder for adding data to your project) to create groups of subjects, or subject sets. If you want to upload your subjects with their associated metadata, however, things become slightly more complex. A subject manifest is a data table that allows you to list image file names alongside associated metadata. By including a manifest with your images to upload, the metadata will remain associated with those images within the Zooniverse platform.
So, what happens if you already have a manifest? Can you upload any type of manifest into Zooniverse? What if you’re working with a specific set of standards?
IIIF (pronounced “triple eye eff”) stands for International Image Interoperability Framework. It is a set of standards for image and A/V delivery across the web, from servers to different web environments. It supports viewing of images as well as interaction, and uses manifests as a major structural component.
If you’re new to IIIF, that’s okay! To understand the work we did, you’ll need three IIIF definitions, all reproduced here from https://iiif.io/get-started/how-iiif-works/:
Manifest: the prime unit in IIIF which lists all the information that makes up a IIIF object. It communicates how to display your digital objects, and what information to display about them, including structure, to varying degrees of complexity as determined by the implementer. (For example, if the object is a book of illustrations, where each illustrated page is a canvas, and there is one specific order to the arrangement of those pages).
Canvas: the frame of reference for the display of your content, both spatial and temporal (just like a painting canvas for two-dimensional materials, or with an added time dimension for a/v content).
Annotation: a standard way to associate different types of content to whatever is on your canvas (such as a translation of a line or the name of a person in a photograph. In the IIIF model, images and other presentation content are also technically annotations onto a canvas). For more detail, see the Web Annotation Data Model.
What we did
For this effort, we worked with Mia and her colleagues at the British Library on an exploratory project to see if we could create a proof of concept for Zooniverse image upload and data export which was IIIF compatible. If successful, these two prototypes could then form the basis for an expanded effort. We used the British Library In The Spotlight Zooniverse project as a testing ground.
Data upload
First, we wanted to figure out a way to create a Zooniverse subject set from a IIIF manifest. We figured the easiest approach would be to use the manifest URL, so Jim built a tool that imports IIIF manifests via a URL pasted into the Project Builder (see image below).
This is an experimental feature, so it won’t show up in your Zooniverse project builder ‘Subject Sets’ page by default. If you want to try it out, you can preview the feature by adding subject-sets/iiif?env=production to your project builder URL. For example, if your project number is #xxx, you’d use the URL https://www.zooniverse.org/lab/xxx/subject-sets/iiif?env=production
To create a new subject set, you simply copy/paste the IIIF manifest URL into the box at the top of the image and click ‘Fetch Manifest’. The Zooniverse uploader will present a list of metadata fields from the manifest. The tick box column at the far right allows you to flag certain fields as ‘Hidden’, meaning they won’t be shown to volunteers in your project’s classification interface. Once you’ve marked everything you want to be ‘Hidden’, you click ‘Create a subject set’ to generate the new subject set from the IIIF manifest.
Export to manifest with IIIF annotations
In the second phase of this experiment, we explored how to export Zooniverse project results as IIIF annotations. This was trickier, because the Zooniverse classification model requires multiple classifications from different volunteers, which are then typically aggregated together after being downloaded from the platform.
To export Zooniverse results as IIIF annotations, therefore, we needed to include a step that runs the appropriate in-house offline aggregation code, then convert the data to the appropriate IIIF annotation format. Because the aggregation step is necessary to produce a single annotation per task, this step is project- and workflow-specific (whereas the IIIF Manifest URL upload works for all project types). For this effort, we tested annotation publishing on the In The Spotlight Transcribe Dates workflow, which uses a simple free-text entry task. The other In The Spotlight workflow has a slight more complex task structure (rectangle marking task + text entry sub-task), which we’re hoping to be able to add to the technical documentation soon.
Now, we need your feedback! The next steps for this work will include identifying community needs and interest – would you use these tools for your Zooniverse project? What features look useful (or less so)? Your feedback will help us determine our next steps. Mostly, we want to know who our potential audiences are, what task types they would most want to use, and what sort of comfort level they have, particularly when it comes to running the annotations code (from “This is great!” to “I don’t even know where to start!”). There are a lot of possible routes we could take from here, and we want to make sure our future work is in service of our project building community.
Try out the In The Spotlight project and help create real data for testing ingest processes.
Mia and I are also part of the IIIF Slack community, so feel free to ping us there.
Finally, a massive “Thank you!” to the British Library for funding this experiment, and to Glen Robson and Josh Hadro at IIIF for their feedback on various stages of this experiment.
Since its founding, a well-known feature of the Zooniverse platform has been that volunteers see (& interact with) image, audio, or video files (known as ‘subjects’ in Zooniverse parlance) in an intentionally random order. A visit to help.zooniverse.org provides this description of the subject selection process:
[T]he process for selecting which subjects get shown to volunteers is very simple: it randomly selects an (unretired, unseen) subject from the linked subject sets for that workflow.
For some project types, this method can help to avoid bias in classification. For other project types, however, random subject delivery can make the task more difficult.
Transcription projects frequently use a single image as the subject-level unit. These images most often depict a single page of text (i.e., 1 subject = 1 image = 1 page of text). Depending on the source material being transcribed, that unit/page is often only part of a multi-page document, such as a letter or manuscript. In these cases, random subject delivery removes the subject (page) from its larger context (document). This can actually make successful transcription more difficult, as seeing additional uses of a word or letter can be helpful for deciphering a particular hand.
Decontextualized transcription can also be frustrating for volunteers who may want greater context for the document they’re working on. It’s more interesting to be able to read or transcribe an entire letter, rather than snippets of a whole.
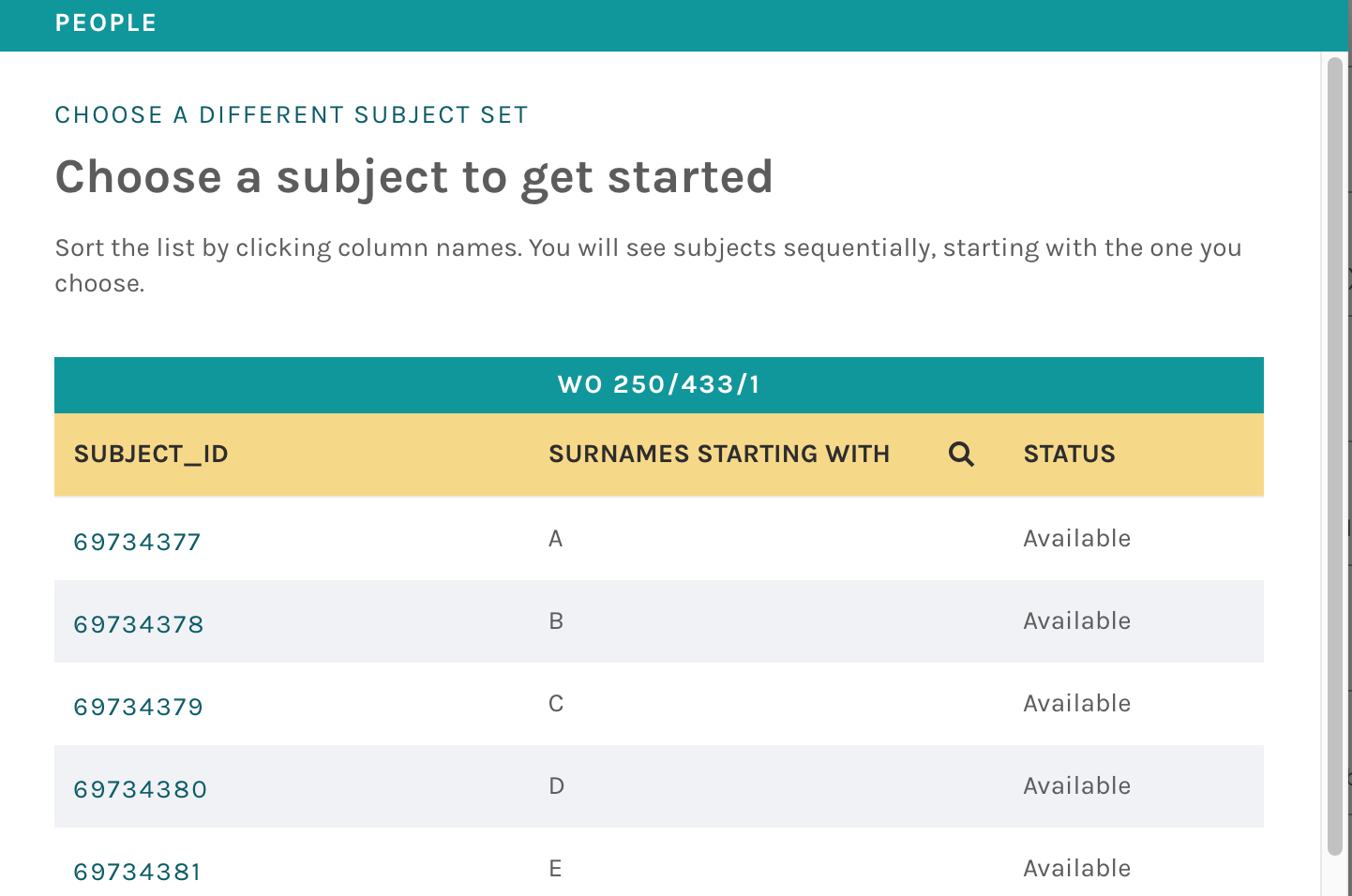
As part of this research project, we have designed and built a new indexing tool that allows volunteers to have more agency around which subject sets—and even which subjects—they want to work on, rather than receiving them randomly.
The indexing tool allows for a few levels of granularity. Volunteers can select what workflow they want to work on, as well as the subject set. These features are currently being used on HMS NHS: The Nautical Health Service, the first of three Engaging Crowds Zooniverse projects that will launch on the platform before the end of 2021.
Subject set selection screen, as seen in HMS NHS: The Nautical Health Service.
Sets that are 100% complete are ‘greyed’ out, and moved to the end of the list — this feature was based on feedback from early volunteers who found it too easy to accidentally select a completed set to work on.
In the most recent iteration of the indexing tool, selection happens at the subject level, too. Scarlets and Blues is the second Engaging Crowds project, featuring an expanded indexing tool from the version seen in HMS: NHS. Within a subject set, volunteers can select the individual subject they want to work on based on the metadata fields available. Once they have selected a subject, they can work sequentially through the rest of the set, or return to the index and choose a new subject.
Subject selection screen as seen in Scarlets and Blues.
On all subject index pages, the Status column tells volunteers whether a subject is Available (i.e. not complete and not yet seen); Already Seen (i.e. not complete, but already classified by the volunteer viewing the list); or Finished (i.e. has received enough classifications and no longer needs additional effort).
A major new feature of the indexing tool is that completed subjects remain visible, so that volunteers can retain the context of the entire document. When transcribing sequentially through a subject set, volunteers that reach a retired subject will see a pop-up message over the classify interface that notes the subject is finished, and offers available options for how to move on with the classification task, including going directly to the next classifiable subject or returning to the index to choose a new subject to classify.
Subject information banner, as seen in Scarlets and Blues.
As noted above, sequential classification can help provide context for classifying images that are part of a group, but until now has not been a common feature of the platform. To help communicate ordered subject delivery to volunteers, we have included information about the subject set–and a given subject’s place within that set–in a banner on top of the image. This subject information banner (shown above) tells volunteers where they are within the order of a specific subject set.
Possible community use cases for the indexing tool might include volunteers searching a subject set in order to work on documents written by a particular author, written within a specific year, or that are written in a certain language. Some of the inspiration for this work came from Talk posts on the Anti-Slavery Manuscripts project, in which volunteers asked how they could find letters written by certain authors whose handwriting they had become particularly adept at transcribing. Our hope is that the indexing tool will help volunteers more quickly access the type of materials in a project that speak to their interests or needs.
If you have any questions, comments, or concerns about the indexing tool, please feel free to post a comment here, or on one of our Zooniverse-wide Talk boards. This feature will not be immediately available in the Project Builder, but project teams who are interested in using the indexing tool on a future project should email contact@zooniverse.org and use ‘Indexing Tool’ in the subject line. We’re keen to continue trying out these new tools on a range of projects, with the ultimate goal of making them freely available in the Project Builder.
“Will all new Zooniverse projects use this method for subject selection and sequential classification?”
No. The indexing tool is an optional feature. Teams who feel that their projects would benefit from this feature can reach out to us for more information about including the indexing tool in their projects. Those who don’t want the indexing tool will be able to carry on with random subject delivery as before.
“Why can’t I refresh the page to get a new subject?”
Projects that use sequential classification do not support loading new subjects on page refresh. If the project is using the indexing tool, you’ll need to return to the index and choose a new page. If the project is not using the indexing tool, you’ll need to classify the image in order to move forward in the order of sequence. However, the third Engaging Crowds project (a collaboration with the Royal Botanic Garden Edinburgh) will include the full suite of indexing tool features, plus an additional ‘pagination’ option that will allow volunteers to move forwards and backwards through a subject set to decide what to work on see preview image below). We’ll write a follow-up to this post once that project has launched.
Subject information banner, as seen in the forthcoming Royal Botanic Garden Edinburgh project.
“How do I know if I’m getting the same page again?”
The subject information banner will give you information about where you are in a subject set. If you think you’re getting the same subject twice, first start by checking the subject information banner. If you still think you’re getting repeat subjects, send the project team a message on the appropriate Talk board. If possible, include the information from the subject information banner in your post (e.g. “I just received subject 10/30 again, but I think I already classified it!”).
This is a guest post from the research team behind The American Soldier in WWII.
As challenges press upon all of us in the midst of the pandemic, the team behind The American Soldier in World War II has some good news to share.
When we initially launched our project on Zooniverse on VE Day 2018, our goal was to have all 65,000 pages of commentaries on war and military service written by soldiers in their own hands transcribed and annotated within a 2-year window – in triplicate, for quality-control purposes. We not only hit that milestone in May 2020, but last week we completed an additional 4th round.
Attracting 3,000-plus new contributors, this extension of the transcription drive took only six months. Beyond allowing more people to engage with these unique and revealing wartime documents, the added round is improving our final project output. Within the next week or so, our top Zooniverse transcribers will begin final, manual verification of these transcriptions and annotations, which have been cleaned algorithmically. If you are a consistent project contributor and interested in helping with final validation, please do let us know by signing up here.
As we move forward with the project, we have created a Farewell Talk board. Since we have had so many incredible contributors to The American Soldier, we would love to hear any parting words our volunteers would like to share with the team and with fellow contributors about your experiences or most memorable transcriptions.
We are so incredibly grateful for the international team of researchers, data and computer scientists, designers, educators, and volunteers who have gotten the project to where it is and in spite of the great upheaval. Thanks to their hard work and dedication, the project’s open-access website remains on track for a spring 2021 launch.
We look forward to sharing more news with you soon. Until then, be well and safe.
Over the past several months, we’ve welcomed thousands of new volunteers and dozens of new teams into our community.
This is wonderful.
Because there are new people arriving every day, we want to take this opportunity to (re)introduce ourselves, provide an overview of how Zooniverse works, and give you some insight on the folks who maintain the platform and help guide research teams through the process of building and running projects.
Who are we?
The core Zooniverse team is based across three institutions:
Oxford University, Oxford UK
The Adler Planetarium, Chicago IL
The University of Minnesota-Twin Cities, Minneapolis MN
We also have collaborators at many other institutions worldwide. Our team is made up of web developers, research leads, data scientists, and a designer.
How we build projects
Research teams can build Zooniverse projects in two ways.
First, teams can use the Project Builder to create their very own Zooniverse project from scratch, for free. In order to launch publicly and be featured on zooniverse.org/projects, teams must go through beta review, wherein a team of Zooniverse volunteer beta testers give feedback on the project and answer a series of questions that tell us whether the project is 1) appropriate for the platform; and 2) ready to be launched. Anyone can be a beta tester! To sign up, visit https://www.zooniverse.org/settings/email. Note: the timeline from requesting beta review to getting scheduled in the queue to receiving beta feedback is a few weeks. It can then take a few weeks to a few months (depending on the level of changes needed) to improve your project based on beta feedback and be ready to apply for full launch. For more details and best practices around using the Project Builder, see https://help.zooniverse.org/getting-started/.
The second option is for cases where the tools available in the Project Builder aren’t quite right for the research goals of a particular team. In these cases, they can work with us to create new, custom tools. We (the Zooniverse team) work with these external teams to apply for funding to support design, development, project management, and research.
Those of you who have applied for grant funding before will know that this process can take a long time. Once we’ve applied for a grant, it can take 6 months or more to hear back about whether or not our efforts were successful. Funded projects usually require at least 6 months to design, build, and test, depending on the complexity of the features being created. Once new features are created, we then need additional time to generalize (and often revise) them for inclusion in the Project Builder toolkit.
To summarize:
Option 1: Project Builder
Free!
Quick!
Have to work with what’s available (no customization of tools or interface design)
Option 2: Custom Project
Funding required
Can take a longer time
Get the features you need!
Supports future teams who may also benefit from the creation of these new tools!
We hope this helps you to decide which path is best for you and your research goals.
To celebrate Citizen Science Day 2019, this coming Saturday 13th April, a different member of the Zooniverse team will be posting each day this week to share with you some of our all-time favourite Zooniverse projects. First off in the series is our Digital Humanities Lead, Dr. Samantha Blickhan.
From CitizenScience.org: “Citizen Science Day is an annual event to celebrate and promote all things citizen science: amazing discoveries, incredible volunteers, hardworking practitioners, inspiring projects, and anything else citizen science-related!”
Here at Zooniverse, we’re excited to participate by highlighting a series of projects that we enjoy. I want to kick things off by showing off a current project that does a great job illustrating one of my favorite things about this type of research: its ability to cross typical academic or discipline-specific boundaries.
Reading Nature’s Library is a transcription project, launched in February 2018, that was created by a team at Manchester Museum. The project invites volunteers to help transcribe labels for the museum’s collections, which include everything from Archery to Numismatics to Zoology, so this project has something for everyone! In the 13 months since their project launched, a community of 2,669 registered Zooniverse volunteers have completed over 9,283(!) subjects.
Beyond the wide-ranging contents of their dataset, this project is a great way to show how projects can affect a range of disciplines. The results of this project could be used for research in a range of disciplines within the sciences (as varied as their collections), not to mention studies of history, archives, and collections management. Furthermore, large amounts of transcribed text can be a useful tool for helping to train machine learning models for Handwritten Text Recognition. Today’s project selection also raises a good point about terminology and models for participatory research. Although this week we are celebrating ‘Citizen Science Day’, not all projects fit into the same ‘Citizen Science’ model, and the use of ‘citizen’ is not intended in a narrow, geographic sense. As we celebrate the efforts by project teams and their communities of volunteers, we also want to acknowledge the work being done to illuminate these differences and work to develop models for inclusivity and sustainability. The following article great place to start if you’re interested in learning more: Eitzel, MV et al. (2017) Citizen Science Terminology Matters: Exploring Key Terms: https://theoryandpractice.citizenscienceassociation.org/articles/10.5334/cstp.96/.
The world's largest and most popular platform for people-powered research. This research is made possible by volunteers—millions of people around the world who come together to assist professional researchers.