As part of our ongoing expansion of the Oxford Zooniverse team, I’m delighted to announce that there are two new jobs available at Zooniverse HQ in Oxford. We’re looking for developers and scientists who are excited at the prospect of helping us find more planets, keep an eye on more animals and generally make the Zooniverse more awesome.
Postdoc in the statistics of citizen science – this might be a scientist with an interest or experience in citizen science, or someone with statistical expertise. In any case we’re looking to take a proper crack at the generic problem of combining classifications to produce consensus.
Both jobs are two year positions, and we’re really excited about expanding the team in Oxford. If you’d like to know more, you can contact me on cjl AT astro.ox.ac.uk or 07808 167288.
As part of a large expansion of the Oxford Zooniverse team, I’m delighted to announce that there are four new jobs available at Zooniverse HQ in Oxford. We’re looking for developers who are excited at the prospect of helping us find more planets, keep an eye on more animals and generally make the Zooniverse more awesome.
These jobs mark the start of the next stage in the Zooniverse’s evolution, and we’re really excited about expanding the team in Oxford. If you’d like to know more, you can contact me on cjl AT astro.ox.ac.uk or 07808 167288.
Anyone browsing the BBC News Technology section last night might have seen an unexpected appearance of a couple of our projects in this story about illegal streaming of Premier League football games. The story started on Saturday with an email from a volunteer pointing out that Virgin Media, a major Internet Service Provider in the UK, were blocking access to Notes From Nature. All is well now, but if you do experience problems please let us know. If you’d like the background, then read on.
You don’t have to hang around the Zooniverse very long to find out that we’re rather proud of our growing list of publications. We think it’s essential that these papers are available to everyone which is why, for example, we’ve been posting versions of the astronomical papers on arXiv’s Astro-Ph. This is where I get papers I want to read, anyway, but there are advantages to occasionally being able to access the ‘real thing’ – the journal’s own version of the paper.
The doors to the Bodelian library in Oxford are labelled by subject. The one on the left here serves both astronomy and rhetoric. Credit : Jim Linwood
I’m delighted, therefore, to say that Oxford University Press, publishers of the journal we most frequently submit papers to have agreed to make all Zooniverse papers completely free to access. This applies to any Zooniverse paper in Monthly Notices of the Royal Astronomical Society (which is neither monthly nor contains notices of the Royal Astronomical Society), so whether you want to read about bulgeless galaxies, the Solar System’s dust, the supernovae we discovered, Planet Hunters results or Milky Way Project bubbles you can now do so from the journal itself.
Anyone interested in astronomy on the web will be aware of the fabulous success of Planetary Resources’ fundraising effort to build and launch the ARKYD space telescope. They’ve already raised more than a million dollars – helped in part by a cunning plan to let you take a picture of yourself in space – but they’re not stopping there. With three days to go, we’re delighted to announce that they’re going to try and help us help Zooniverse volunteers hunt for potentially hazardous asteroids.
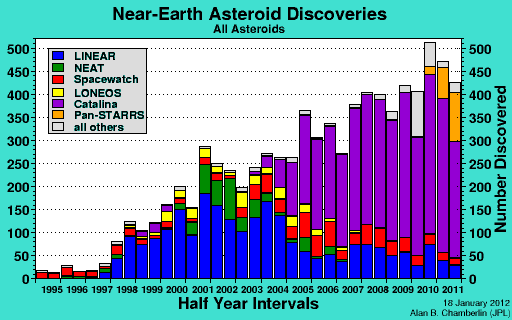
The latest stretch goal is to support the development by the Zooniverse of a citizen science asteroid hunt. If the new target is hit, we’ll build a system that uses more than 3 million images, taken data from the Catalina Sky Survey – the survey responsible for nearly half of the near Earth asteroid discoveries in the last fifteen years. We know there are asteroids out that are waiting to be discovered, and we’re willing to bet that the existing routines used to scan through the survey data didn’t find them all.
Recent discoveries of near-Earth objects; Catalina’s the big purple part.
Anyone who’s followed the Zooniverse over the last few years knows that we believe in doing projects that make authentic contributions to science, and so I’m especially pleased that the project with Planetary Resources is also focused on improving machine learning solutions to asteroid hunting. Rather like our supernova project, an ideal outcome would be to use the classifications provided by volunteers to improve automated searching and suggest new methods by which machines might take up the strain. In the meantime, though, there are new (small) worlds to find – with your help, we’ll be launching the search for them soon.
I’ve put my money where my mouth is already, and if you can afford it then I hope you’ll follow the link and donate so we can all go asteroid hunting. You can also watch their Kickstarter video to see what they’re trying to do.
I was slightly surprised to see my twitter feed this morning filling up with comments about how the term ‘citizen’ appears in writing about science, and about public engagement with science. This seems to be coming from Roland Jackson’s post in response to the publication of a report called ‘What publics? When?’ from Sciencewise, an organisation that gives advice on science policy to government. Roland’s point is that perhaps the reason we get ourselves in a tangle when talking about public engagement is the word ‘public’, thinking that ‘citizen’ does a better job of breaking down the divide between ‘us’ doing the engagement and the ‘public’ being engaged. (There’s another engaging comparison on Nottingham’s ‘Making Science Public’ blog.)
In such contexts, I reckon ‘citizen’ comes up most often in ‘citizen science’, and I thought it might be interesting to say something about our use of the term. It’s how we describe our projects in papers, and we chose it mostly because we didn’t like the term ‘crowdsourcing’, which never seem adequate for projects which very quickly demonstrated that they could grow way beyond simple requests for a community to complete a task. We quickly realised we wanted people to make discoveries, to follow them up themselves and to chase down their own research questions and crowdsourcing just doesn’t describe that. I also liked the fact that anyone – professional or amateur, project designer or participant – could be a citizen scientist.
We clearly weren’t that confident, though. Although the core collaboration that builds and runs the Zooniverse is the Citizen Science Alliance, we’ve mostly reserved that term for grant applications rather than using in the real word. (Let along the problems of being a citizen science group which produces humanities projects either deliberately or accidentally.) This reticence isn’t misplaced; it reflects my firm belief that noone in the history of the world has ever set down at a computer, opened their web browser and thought ‘I’m a citizen scientist. Let’s do some citizen science’. Zooniverse participants are fans of one or more of our projects, and they tend to have stumbled in and then found a comfortable environment where they can do exciting things, rather than started off by looking for a science project. (This is also, I think, reflected in the lack of traffic we get from citizen science portals like SciStarter.)
‘Citizen’ science, from this perspective isn’t any more inclusive than talking about ‘public engagement’. The most common alternative (‘PPSR’ or Public Participation in Scientific Research) doesn’t help either. If names are important, we need a new one for this thing that we’re doing, but as the person who has been most consistently wrong about naming Zooniverse projects (I voted against Galaxy Zoo, for starters!) I’m the last person to ask. Maybe we should crowdsource a solution….
Chris
PS I’m reminded of this slide deck from Arfon which proposes CBSR (Community Based Scientific Research) and PPFCSM (Public Participation as a Fundamental Component of the Scientific Method), although I think he’s kidding on the last one.
Hello for the Martin Wood Lecture Theatre in Oxford’s Department of Physics which is playing host to a crowd of Zooniverse volunteers and project members for ZooCon13. We’re recording the talks for later broadcast, but as a sneak preview I thought I’d liveblog the event.
Talk 1 – SpaceWarps
We’re kicking off with Aprajita Verma from Oxford and from Space Warps, the newest Zooniverse astronomy project. As is traditional when talking about gravitational lensing – the bending of light by matter, she’s using Phil Marshall’s Galaxy in a Wine Glass video.
SpaceWarps is much needed – LSST, the next generation of survey telescope, will produce something like 10000 galaxy scale lenses. It’s designed to map a very wide area of sky, which is perfect for finding rare things like lenses – and this will produce a lot of work as traditional lens hunting is very labour intensive. Not only do they need to be found, but they then need to be modeled.
There are three lenses in this image – one real, and two simulated. Spotting the difference is hard…
Luckily – we have effort! 2 million 6 million classifications have been recorded already from over 8000 people. Particularly pleasing for me is that 40% of those people are discussing things on Talk – this is essential as lenses are complicated things and the interesting ones are going to be found through discussion. The team are doing dynamic assessment of the results, retiring images that no longer need classification – I especially liked their division of classifiers into ‘Optimists’ – who get lenses right but also get excited about lots of things that aren’t lenses – ‘Pessimists’ – who correctly dismiss non-lenses but get rid of lenses too – the ‘Astute’, who get everything right and the ‘Obtuse’, those who get everything wrong. Luckily, we have lots of astute classifiers and almost none who are obtuse, as evidenced by a sneak preview of the first few discoveries (more on those next week).
Talk 2 – Cosmic Evolution from Galaxy Zoo
Next up is Karen Masters of Portsmouth and Galaxy Zoo, talking about science results from the Zooniverse’s oldest project. It’s already clear there is lots of ground to cover in this conference and Karen’s bounding through a brief history of observational astronomy, noting the conceptual leap required to go from thinking about the Milky Way, our galaxy, and an expanding Universe filled with billions of the blighters. Karen just showed a cool movie showing the parts of the sky that have been mapped by the Sloan Digital Sky Survey, which provided images for the early incarnations of Galaxy Zoo.
A Galaxy in need of classifications.
In going through the history of Galaxy Zoo, Karen reminds me that the original BBC news story on Galaxy Zoo claims that we hope that 30,000 people will eventually take part. We smashed that on day one if I remember correctly. (There’s also a factual error in that news story – if anyone tells me what it is via Twitter (@chrislintott) or in person they can have a pint). While I relieve ancient history, Karen’s talking about her work on red spirals: most spirals are blue, but Galaxy Zoo helped us find lots of red ones and Karen says that the Milky Way may even be on its way to becoming one. The work on the red spirals was part of a serious shift in how we think about galaxy formation – a few years back that story was all about mergers but now it’s thought that lots of galaxies form and evolve (including fading from being a blue spiral to a red spiral) in slower, less spectacular ways.
Of course, one of the advantages of citizen science that Galaxy Zoo demonstrated was the ability of classifiers to discover the weird and wonderful. Recent examples include the bulgeless galaxies – spirals which are guaranteed not to have had a merger within the last few billion years – and a set of galaxies (mostly red spirals!) with massive bars at their centre. In even better news, we have time on the Very Large Array (I REPEAT – WE HAVE TIME ON THE VERY LARGE ARRAY!) to follow up on these things.
WE GOT TIME ON THE VERY LARGE ARRAY (this is a picture of some of it)
I’m really quite excited about the VLA. I’ve always wanted to use it.
Talk 3 – New Uses for Old Weather
We’re taking a break from astronomy with Philip Brohan from the Old Weather project – he’s explaining that scientists need historical observations to constrain their models of how the climate behaves. Lacking the ability to stick a weather satellite in the Tardis and head back in time, we need to scrabble around for old records, an idea that dates back to Beaufort of wind scale fame.
Philip in the gloaming, beneath an Old Weather slide.
This is great, but the supercomputers can’t read the 73 million logbook pages we’d like to sort through – hence the need for volunteers. So far more than a million logbook pages have been processed by the project – a small fraction of the total needed but a very useful quantity! Most of these volunteers are attracted by the historical information that the logs fortuitously contain – Philip is currently beneath a slide showing a log book containing both the information that the ship’s company are fitted with seal-skin boots, and that 23 dogs are received on board. (Why? Surely not for food…).
It’s all got a bit gruesome now – six dead bodies are being placed in alcohol. Luckily we’re swiftly on to HMS Tarantula, where their anemometer is infested with ants. The current set of logbooks have more famous events; in particular, the logbooks of the Jeannette show the discovery of the Arctic island now named after it (upon which nothing but ice sheets grow). The fact that we have these logbooks at all is a miracle; the ship was crushed by the ice and the crew (most of whom perished) chose to carry the scientific records with them as they struggled to safety.
Images from and about the Jeanette, including in the bottom left an artist’s impression of the chest of logbooks being saved.
As well as the climate and the history, Phil says, the third important aspect of Old Weather is the people. The project’s made particularly good use of the forum, which has steered the project in new directions and provided a home for discussion of things we never thought to look for, as well as art and verse. The latter was particularly inspired by the tragic loss of the chocolate aboard the HMS Manuta. Before rolling the credits listing his more than 17,000 collaborators, Philip ended these tales by noting that to make a serious dent on the archives we need to speed up by a factor of ten, a challenge the Zooniverse is happy to accept.
Talk 4 – The Future of Galaxy Zoo
Back to the Universe now, and Oxford’s Brooke Simmons is able to start her talk on what’s coming up for Galaxy Zoo by reminding the crowd that the data release paper for the second version of Galaxy Zoo is now with the referee. At about 30 pages, it’s as short as it could possibly be, showing the amount of effort that goes into dealing with classifications received via a large citizen science project.
Brooke’s now explaining the need – with Galaxy Zoo trying to reach back to a time not that long after the Big Bang – for us to use all sorts of tests to understand how our classifications work. Showing images of the same galaxies shifted to higher and higher redshifts (further and further away) it’s clear that classifications will change just because it’s harder to see what’s going on when galaxies get further away. We’re also playing with supercomputer simulations of the evolution of galaxies which shows how things change over time.
It’s not all about simulations, though – we’re thinking about moving beyond the optical range of the spectrum and looking at galaxies in the ultraviolet and infrared. The former, from a satellite called GALEX, shows only the youngest starts, the latter, from a survey called UKIDSS which covers about a third of the Sloan area, the dust and older stars. Also on the agenda are more advanced tools, like those which power the Galaxy Zoo Navigator which allows primarily school groups to look at the statistics of their classifications.
Correction I wasn’t listening properly to Aprajita; Spacewarps got 2 million classifications in the first week, and at the time of ZooCon was over 6 million. I’ve corrected the post. 1st July 2013.
One of the joys of working in the Zooniverse is the sheer variety of people who are interested in our work, and I spent a happy couple of days toward the end of last year at a symposium about Discovery Infomatics – alongside a bunch of AI researchers and their friends who are trying to automate the process of doing science. I don’t think they’d mind me saying that we’re a long, long way from achieving that, but it was a good chance to muse on some of the connections between the work done by volunteers here and by our colleagues who think about machine learning.
I’m still convinced that that will especially be needed as the size of datasets produced by scientific surveys continues to increase at a frightening pace. The essential idea is that only the proportion of the data which really needs human attention need be passed to human classifiers; an idea that starts off as a non-brainer (wouldn’t it be nice if we could decide in advance which proportion of Galaxy Zoo systems are too faint or fuzzy for sensible decisions to be made?) and then becomes interestingly complex.
This is particularly true when you start thinking of volunteers not as a crowd, but as a set of individuals. We know from looking at the data from past projects that people’s talents are varied – the people who are good at identifying spiral arms, for example, may not be the same people who can spot the faintest signs of a merger. So if we want to be most efficient, what we should be aiming for is passing each and every person the image that they’d be best at classifying.
That in turn is easy to say, but difficult to deliver in practice. Since the days of the original Galaxy Zoo we’ve tended to shun anything that resembles a test before a volunteer is allowed to get going, and in any case a test which thoroughly examined someone’s ability in every aspect of the task (how do they do on bright galaxies? on faint ones? on distant spirals? on nearby ellipticals? on blue galaxies? what about mergers?) wouldn’t be much fun.
One solution is to use the information we already have; after all, every time someone provides a classification we learn something not only about the thing they’re classifying but also about them. This isn’t a new idea – in astronomy, I think it’s essentially the same as the personal equation used by stellar observers to combine results from different people – but things have got more sophisticated recently.
As I’ve mentioned before, a team from the robotics group in the department of engineering here in Oxford took a look at the classifications supplied by volunteers in the Galaxy Zoo: Supernova project and showed that by classifying the classifiers we could make better classifications. During the Discovery Infomatics conference I had a quick conversation with Tamsyn Waterhouse, a researcher from Google interested in similar problems, and I was able to share results from Galaxy Zoo 2 with her*.
We didn’t get time for a long chat, but I was delighted to hear that work on Galaxy Zoo had made it into a paper Tamsyn presented at a different conference. (You can read her paper here, or in Google’s open access repository here.) Her work, which is much wider than our project, develops a method which considers the value of each classification based (roughly) on the amount of information it provides, and then tries to seek the shortest route to a decision. And it works – she’s able to show that by applying these principles we would have been done with Galaxy Zoo 2 faster than we were – in other words, we wasted some people’s time by not being as efficient as we could be.
A reminder of what Galaxy Zoo 2 looked like!
That doesn’t sound good – not wasting people’s time is one of the fundamental promises we make here at the Zooniverse (it’s why we spend a lot of time selecting projects that genuinely need human classifications). Zoo 2 was a long time in the past, but knowing what we know now should we be implementing a suitable algorithm for all projects from here on in?
Probably not. There are some fun technical problems to solve before we could do that anyway, but even if we could, I don’t think we should. The current state of the art of such work misses, I think, a couple of important factors which distinguish citizen science projects from other examples considered in Tamsyn’s paper particularly. To state the obvious: volunteer classifiers are different from machines. They get bored. They get inspired. And they make a conscious or an unconscious decision to stay for another classification or to go back to the rest of the internet.
The interest a volunteer will have in a project will change as they move (or are moved by the software) from image to image and from task to task, and in a complicated way. Imagine getting a galaxy that’s difficult to classify; on a good day you might be inspired by the challenge and motivated to keep going, on a bad one you might just be annoyed and more likely to leave. We all learn as we go, too, and so our responses to particular images change over time. The challenge is to incorporate these factors into whatever algorithm we’re applying so that we can maximise not only efficiency, but interest. We might want to show the bright, beautiful galaxies to everyone, for example. Or start simple with easy examples and then expand the range of galaxies that are seen to make the task more difficult. Or allow people a choice about what they see next. Or a million different things.
Whatever we do, I’m convinced we will need to do something; datasets are getting larger and we’re already encountering projects where the idea of getting through all the data in our present form is a distant dream. Over the next few years, we’ll be developing the Zooniverse infrastructure to make this sort of experimentation easier, looking at theory with the help of researchers like Tamsyn to see what happens when you make the algorithms more complicated, and talking to our volunteers to find out what they want from these more complicated projects – all in our twin causes of doing as much science as possible, while providing a little inspiration along the way.
* – Just to be clear, in both cases all these researchers got was a table of classifications without any way of identifying individual volunteers except by a number.
We were delighted by the response to our call for volunteers to attend our project workshop and we’re delighted to announce that our two winners are Katy Maloney and Janet Bain. Katy is a Planet Hunter from Montreal (you can see her in this recent video about online communities. Janet is well known to those from Old Weather where she serves as moderator of the very active forum.
As Jules explained in her post, these workshops are a chance for the strange mix of people behind the scenes of the Zooniverse – developers, educators and scientists – to get together to discuss what works and what doesn’t, and to plan the year ahead. We think it’s very important to have volunteers there – and we hope that Katy and Janet (along with Jules, who we’ve invited back) will keep you all informed and involved in the discussions.
There were a few comments in the discussion under that last post from people – particularly locals – who would clearly have dearly loved to come. Unfortunately, it wouldn’t be possible to run the workshop as a public event; both because of the format (which features spontaneously arranged small group discussions) and also to allow everyone to speak freely about often quite difficult issues. What I do find heartening is that we’ve grown a community who want to help us plan and develop for the future, and we need to take that seriously.
I’ll write more over the next couple of weeks and months about what we’re going to do to be more open, but for now for those who really wanted to come we’ll work hard to organise some truly public events. We have a meeting in Oxford on the 22nd June which I hope British Zooites will be able to attend, and we’ll arrange a similar event in Chicago as soon as possible. We’ll also try hard to webcast these events so all can attend.
I’ve been remiss in not posting our latest job advert on the blog – it’s a full-time developer position in Oxford for someone to lead our new collaboration with Imperial War Museum’s project to commemorate the first world war. This is an exciting chance to expand what we’ve been doing with projects like Old Weather and we hope that talented front-end developers will apply.
We’re looking for someone who can build beautifully in HTML5/CSS/Javascript, and who has an understanding of user interface design. If they’re good at working with large and diverse teams, that’d be a bonus too as they’ll be the main point of contact between Zooniverse and IWM. A background in developing highly-usable interfaces for web applications and experience of working with a modern web framework such as Ruby on Rails would be an advantage, as would a history in citizen science, history, science or any combination of the three.
Full details are here, but the upshot is that you’ve got until 5th March to apply.
The world's largest and most popular platform for people-powered research. This research is made possible by volunteers—millions of people around the world who come together to assist professional researchers.